Diskussion:Perzeptron
Mehrlagiges Perzeptron - Topologien
[Quelltext bearbeiten]"Alle Neuronen einer Schicht sind vollständig mit den Neuronen der nächsten Schicht vorwärts verknüpft (Feedforward-Netze). Weitere Topologien haben sich ebenfalls bewährt: Fully connected: Die Neuronen einer Schicht werden mit allen Neuronen der direkt folgenden Schichten verbunden"
Das ist doch das selbe, und keine "weitere" Topologie, oder? Oder ist bei dem zweiten gemeint, dass die Neuronen mit allen Neuronen ALLER folgender Schichten verbunden sind? Wobei ich davon noch nie gehört habe, und dann die Formulierung "der direkt folgendenden Schichten Käse ist. (nicht signierter Beitrag von 212.121.145.5 (Diskussion)) 14:57, 24. Jul. 2019 (CEST)
- Feed-forward-Netz war falsch definiert. Habs korrigiert.--Tminus7 17:55, 24. Jul. 2019 (CEST)
Mehrlagiges Perzeptron (Full-Connection)
[Quelltext bearbeiten]"Full-Connection: Die Neuronen einer Schicht werden mit den Neuronen aller folgenden Schichten verbunden."
Das ist doch falsch? Oder verwechsel ich das gerade mit einem Fully Connected MLP?
Ich bin der Meinung das wäre richtig: "Die Neuronen einer Schicht werden mit allen Neuronen der folgenden Schicht verbunden."
Dazu kann man dann auch sagen, dass der MLP vollständig ist.
Den Begriff Full-Connection habe ich noch nie so gehört (sondern nur full connectivity oder so...). (nicht signierter Beitrag von 193.175.2.18 (Diskussion) 21:12, 24. Jul 2016 (CEST))
- Es heißt "fully connected". (Wenn man von einer Schicht redet sagt man manchmal auch "dense layer") Ich habe es verbessert. Danke für den Hinweis. --Martin Thoma 06:04, 25. Jul. 2016 (CEST)
Schichten des Perzeptrons in Graphik
[Quelltext bearbeiten]Hallo, das in der ersten Graphik gezeigte Perzeptron wird als dreilagig bezeichnet. Müsste das nicht zweilagig heißen? Gezählt werden meines Wissens ja die Gewichtsschichten (hier 2; nicht die Neuronenschichten, hier 3). Gruß Chris (nicht signierter Beitrag von 79.237.190.35 (Diskussion) 12:23, 19. Mär. 2011 (CET))
- Hallo, ich kenne beide Varianten, also dass die Eingabeschicht auch mitgezählt wird. Aber hier bei der Wikipedia sollte es einheitlich sein, womit du also recht hast. Viele Grüße, --Adrian Lange ☎ 13:02, 19. Mär. 2011 (CET)
Lem
[Quelltext bearbeiten]Ich glaube, daß das Wort Perceptron noch mindestens eine weitere, von der im Artikel erklärten verschiedene Bedeutung hat; nämlich jene, die Stanisław Lem in seinem Buch ,,Summa Technologiae" verwendet. Ich habe gerade wirklich nicht die Zeit, das einzubauen oder zu entscheiden, ob dies unnötig ist, aber vielleicht fühlt sich ja jemand anders dazu berufen. -Franek 15:51, 20. Okt 2005 (CEST)
- Ich bin mir ziemlich sicher das Lem damit genau das meinte, was hier im Artikel beschrieben wird. --Cubefox 16:04, 18. Sep. 2010 (CEST)
Link?
[Quelltext bearbeiten]Hi alle! Ich habe gerade einen aufn Sack bekommen wegen Verlinken. Mein anliegen ist Folgendes: Das Skript
- Ein kleiner Überblick über Neuronale Netze (D. Kriesel) - Grösstes kostenloses Skriptum (knapp 200 Seiten, PDF, 4.6MB) in Deutsch zu Neuronalen Netzen. Sehr reich Illustriert und anschaulich. Enthält ein Kapitel über das Perceptron, Delta-Regel und Backpropagation samt Motivation, Herleitung und Variationen wie z.B. Trägheitsterm, Lernratenvariationen u.a.
Enthält zwar NUR EIN KAPITEL über das Perzeptron, aber es ist erstens das grösste kapitel des Skriptes und zweitens ausführlicher als der Artikel hier. Ich finde also das irgendwie ein Grenzfall zu den Linkregeln aber der Artikel hier würde durch den Link vervollständigt. Wenn ihr das auch so seht: Setz doch einer einfach den Link rein. So ist gewährleistet, dass ich nicht Spamme ;)
Henrik (falsch signierter Beitrag von 212.201.72.253 (Diskussion) 4:11, 9. Mär. 2007 (CET))
Anderes Perzeptron?
[Quelltext bearbeiten]Hallo. Für mich war bis gerade ein Perzeptron ein Maschienen Lernalgorithmus, der Datenpunkte mit zwei Verschiedenen Labels in einem Vektorraum durch aufrechterhalten / anpassen einer trennen Hyperebene klassifieziert. Ist das jetzt irgendwie mit diesem hier verwandt?(nicht signierter Beitrag von 83.135.128.20 (Diskussion) )
- Ja, die Betrachtung fehlt nur noch. --chrislb 问题 14:00, 10. Mai 2006 (CEST)
- Kann auch mittels Sigmoidfunktionen im versteckten Layer modelliert werden. Der lineare Eingangslayer bildet das Skalarprodukt des Eingangsvektors mit einem zu lernenden Vektor, welcher als Normalenvektor auf die trennende Hyperebene gesehen wird. Der Sigmoidallayer schaltet, je nachdem ob das Skalarprodukt positiv (Eingangsdaten auf der einen Seite der Hyperebene) oder negativ (Daten auf der anderen Seite) war.(nicht signierter Beitrag von 84.151.93.239 (Diskussion) )
Datum
[Quelltext bearbeiten]Auf der englischen Seite wird als Entwicklungsdatum das Jahr 1957 genannt, hier ist nun zu lesen, daß das Perzeptron 1958 zuerst vorgestellt wurde. Sollte man hier nicht vielleicht auch das Jahr 1957 nennen?--BobaFett 15:16, 17. Mär 2006 (CET)
- Dafür sollte dann eine Quellenangabe hinzugezogen werden. Solche Angaben sind oft auf ein Jahr ungenau, da nicht klar ist, welche Publikation als Begründung angesehen werden kann. --chrislb 问题 11:37, 18. Apr 2006 (CEST)
Mehrlagiges Perzeptron
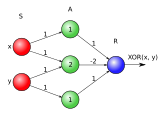
[Quelltext bearbeiten]meiner meinung nach sind 2 neuronen auf der mittleren schicht (in verbindung mit einem symmetrischen linear threshold als transferfunktion) ausreichend, um ein XOR abzubilden. 3 verdeckte neuronen (wie auf dem bild gezeigt) sind meiner meinung nach nicht notwendig. King gabson 23:56, 30. Mai 2006 (CEST)
- Gebe doch einfach die Gewichtungen an, und dann können wir immer noch schauen, ob die Grafik vereinfacht werden kann. --chrislb 问题 00:54, 31. Mai 2006 (CEST)
lange hat's gedauert, aber jetzt melde ich mich wieder zu wort (hatte ziemlich viel zu tun --> matura.)
es reicht ein netz mit folgenden charaktristiken:
netzarchitektur (neuronen-zahl): 2 input, 2 middle, 1 output
gewichte: alle 1 bis auf das zw. N11 und N22 und das zw. N12 und N21 - die sind jeweils -1.
transferfunktion: threshold unsymmetrisch - m = 0, n = 1
King gabson 22:14, 26. Jun 2006 (CEST)
- Wenn du noch sagst, was und sind. --chrislb 问题 22:27, 26. Jun 2006 (CEST)
- so, jetzt hab ich die matura hinter mir. wenn du ganz kurz zeit hast, dann mal ich sogar eine skizze davon :-) King gabson 09:50, 29. Jun 2006 (CEST)


so - meine version findest du hier. die transferfunktion und die propagationsfunktion sind da zu finden
- Sieht gut aus. Vielleicht ist das Beispiel mit 3 Neuronen ein Tick intuitiver? --chrislb 问题 00:30, 5. Jul 2006 (CEST)
Beweis des Konvergenztheorems
[Quelltext bearbeiten]Im Text steht Rosenblatt selbst hätte das Konvergenztheorem bewiesen. Das ist aber wohl nicht der Fall. In dem Buch "Computer -- neue Flügel des Geistes?" von Klaus Mainzer heißt es auf S. 304: "Zunächst sei ein wichtiges positives Ergebnis festgehalten, das bei Rosenblatt durchaus offen war. Gemeint ist das Perzeptron-Konvergenz-Theorem: [...]" Es scheint vielmehr, dass Minsky und Papert 1969 in ihrem Buch "Perceptrons" dieses Theorem bewiesen. -- Philonous 12:10, 7. Jun. 2010 (CEST)
- Das ist richtig. Rosenblatt hat zwar das Perzeptron-Konvergenz-Theorem formuliert, mathematisch bewiesen hat es allerdings erst Minsky (und damit die Forschung mit neuronalen Netzen vorerst ausgebremst). Du kannst den Text gerne anpassen ;-) Viele Grüße, --Adrian Lange ☎ 12:54, 19. Mär. 2011 (CET)
Bild
[Quelltext bearbeiten]Hallo zusammen,
ich würde gerne das Bild ersetzen:
-
 Alt
Alt -
 Neu
Neu -
 Alt
Alt -
 Neu
Neu




{kind=link}
{kind=link}
Gibt es Verbesserungsvorschläge / Einwände?
Grüße, --Martin Thoma 15:24, 25. Aug. 2013 (CEST)
- Da es anscheinend nichts zu beanstanden gibt, habe ich es mal ersetzt --Martin Thoma 12:54, 10. Sep. 2013 (CEST)
- Das XOR Bild stellt ein mehrlagiges lineares Perceptron dar. Es gibt keinerlei Hinweis das ein nichtlineares Layer verwendet wird. Damit kann das gezeigte Netz das XOR Problem nicht lösen bzw. separieren. Wenn man das Netz mit den gezeigten Gewichten und Bias linear nachrechnet sieht man das auch:
- x,y -> XOR
- 0,0 -> -1
- 0,1 -> -2
- 1,0 -> -2
- 1,1 -> -3
- Wahrscheinlich beziehen sich die angegebenen Gewichte und Bias auf eine Version mit nicht linearer Aktivierungs Funktion welche im wiki "verloren" gegangen ist. (nicht signierter Beitrag von LuposWiki (Diskussion | Beiträge) 17:46, 24. Jun. 2019 (CEST))
- Das Bild passt schon. Du hast dich verrechnet.--Tminus7 17:02, 25. Jun. 2019 (CEST)
Ich habe mich nicht verrechnet, ich dachte fälschlicherweise ein Perceptron hat keine Aktivierungsfunktion. Hat es aber doch es ist die Heavyside/Stufen Funktion, damit passt das Bild doch. (nicht signierter Beitrag von 82.218.180.58 (Diskussion) 18:54, 25. Jun. 2019 (CEST))
Perzeptron-Lernregel falsch?
[Quelltext bearbeiten]Die Perzeptron-Lernregel hier ignoriert komplett den Bias. Wie wird dieser also gelernt? Es wäre natürlich möglich, den Bias in w mit zu absorbieren, das scheint hier geschehen, wird jedoch nie explizit erwähnt? (nicht signierter Beitrag von 80.151.176.245 (Diskussion) 11:44, 6. Jul. 2021 (CEST))
Aktivierungsfunktion
[Quelltext bearbeiten]Ich habe ein Probleme, bei denen ich nicht weiß, wie man sie sinnvoll löst:
- In Perzeptron#Berechnung der Ausgabewerte wird die Aktivierungsfunktion der McCulloch-Pitts-Zelle eingeführt, aber die Begriffe
- fehlen.
- Mir ist nicht klar, ob mit Perzeptron ein Netz aus McCulloch-Pitts-Zellen gemeint ist, oder ob Zellen mit beliebiger Sigmoidfunktion als Aktivierungsfunktion gemeint sind. Der Abschnitt Perzeptron#Berechnung der Ausgabewerte beschreibt nur ein Netz aus McCulloch-Pitts-Zellen während der Abschnitt Perzeptron#Mehrlagiges Perzeptron auf Backpropagation referenziert und damit Zellen mit differenzierbarer Aktivierungsfunktion meint; also gerade keine McCulloch-Pitts-Zelle.