Internationales Phonetisches Alphabet
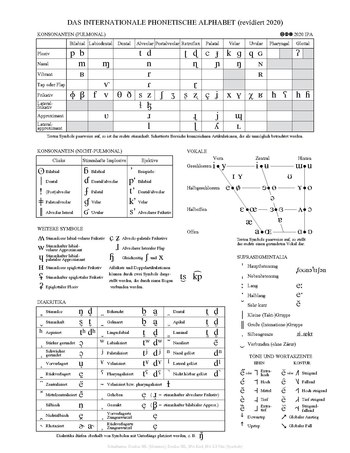
Das Internationale Phonetische Alphabet (kurz IPA) ist ein phonetisches Alphabet und somit eine Sammlung von Zeichen, mit deren Hilfe die Laute aller menschlichen Sprachen nahezu genau beschrieben und notiert werden können. Es wurde von der International Phonetic Association (kurz IPA) entwickelt, kam in seinem ersten Entwurf 1888 heraus und ist die heute am weitesten verbreitete Lautschrift.
Die aktuellen IPA-Zeichen und ihre Aussprachen sind in der Liste der IPA-Zeichen aufgeführt.
Geschichte
[Bearbeiten | Quelltext bearbeiten]Die wichtigsten Versuche vor dem 19. Jahrhundert in Europa, ein universales phonetisches Alphabet zu schaffen, waren jene von John Wilkins im Jahr 1668, von Francis Lodwick (1619–1694) im Jahr 1686, von Charles de Brosses im Jahr 1765, von William Jones im Jahr 1788 und von William Thornton im Jahr 1793. Weitere Vorschläge stammten von John Pickering im Jahr 1818 und Constantin François Volney 1795. Vorschläge von Isaac Pitman 1837 und 1842 sowie von Alexander John Ellis 1845, 1847 und seiner Essentials of Phonetics, containing the theory of a universal alphabet 1848 sollten später bei der Schaffung des Internationalen Phonetischen Alphabetes übernommen werden. Weitere Vorläufer waren Samuel Haldeman (1812–1880) mit seiner Analytic Othography 1858/1860, Karl Moritz Rapp und seine Physiologie der Sprache (1836–1841), Ernst Brücke (1819–1892) mit Grundzüge der Physiologie 1856 und 1963, Carl Merkel (1812–1876) und seine Physiologie der menschlichen Sprache (physiologische Laletik) 1866, Moritz Thausing mit Das natürliche Lautsystem der menschlichen Sprache 1863, Félix du Bois-Reymond (1782–1865) und seine Schrift Kadmus von 1862.
Als Meilenstein gilt das Werk von Karl Richard Lepsius, der 1852 im Auftrag der Church Missionary Society ein Alphabet vorschlug, das zum Ziel hatte, alle Sprachen der Welt, vor allem aber afrikanische ohne eigenes Schriftsystem, schreiben zu können. Ein Mitbewerber von Lepsius war Friedrich Max Müller. Das „Standardalphabet“ von Lepsius wurde mit Anpassungen u. a. von dem Afrikanisten Carl Meinhof und von dem Missionar Karl Endemann (1836–1919) verwendet, und auch das phonetische Alphabet des Missionars Wilhelm Schmidt (1845–1921) beruhte auf den Symbolen von Lepsius.

Im Jahr 1867 erschien Visible Speech, the Science of Universal Alphabetics von Alexander Melville Bell, das eine recht abstrakte, ikonische Lautschrift vorstellte; 1877 veröffentlichte sein Schüler Henry Sweet ein Handbook of Phonetics, in dem er mit Bezug auf Bell und auf Ellis wieder ein System auf Grundlage des lateinischen Alphabetes vorschlug.
Der französische Linguist Paul Passy (Le maître phonétique) initiierte die Entwicklung des „Internationalen Phonetischen Alphabets“, dessen Entwürfe 1888 publiziert wurden.[1] Er war auch erster Präsident der International Phonetic Association (noch als Dhi Fonètik Tîtcerz' Asóciécon FTA) von 1886 bis 1888.[2] Eine Arbeitsgruppe von Phonetikern gründete 1886 die Association Phonétique Internationale und entwarf das für die Anwendung auf alle Sprachen angelegte internationale phonetische Alphabet IPA. Henry Sweet, der George Bernard Shaw zur Figur des „Henry Higgins“ in seinem bekannten Schauspiel Pygmalion inspirierte, war aktives Mitglied der Gruppe.[3] In Kiel fand 1989 die International Phonetic Association Kiel Convention statt, die nach mehr als einem Jahrhundert eine wesentliche Überarbeitung des IPA brachte.[4] Kleinere Revisionen fanden auch 1993 und 1996 statt.
Praktische Bedeutung
[Bearbeiten | Quelltext bearbeiten]Das IPA stellt eine wesentliche Erleichterung der Darstellung der Aussprache in Wörterbüchern und Lexika dar. Beim Lesen von IPA-Texten ist jedoch auch Vorsicht geboten:
Bei manchen Sprachen, z. B. dem Französischen, gibt es eine allgemein akzeptierte Standardaussprache (Orthophonie), bei anderen nicht. Eine amtlich festgesetzte Aussprache kann allerdings im Alltag ungebräuchlich sein. Die landesübliche Bandbreite eines Lautes kann wesentlich größer sein (z. B. die deutsche Endsilbe -er) als der Unterschied ähnlicher Lautzeichen. Was in einer Sprache als korrekt oder falsch, als normal oder fremdartig, als verständlich oder unverständlich aufgefasst wird, ist für jemanden, der die Sprache nur selten oder noch nie gehört hat, nicht zu ermessen.
In Wörterbüchern wird nicht selten ein vereinfachter Zeichensatz verwandt, um Leser ohne Vorkenntnisse nicht zu verwirren.[5] So unterscheidet Cassell’s German Dictionary weder die verschiedenen Aussprachen des deutschen r, noch die offenere Aussprache eines kurzen a, i, u und ü gegenüber dem jeweiligen langen Vokal. Die Aussprache des englischen no wird aus Tradition allgemein als [] wiedergegeben, obwohl im Britischen tatsächlich [] gesagt wird. Üblicherweise wird auch nicht berücksichtigt, dass in manchen Sprachen ohne sch-Laut [ʃ] das s zumeist eher wie [ɕ] (zwischen s [s] und Ich-Laut [ç]) ausgesprochen wird, beispielsweise im europäischen Spanisch und im Griechischen (eine phonetisch genauere Beschreibung ist wahrscheinlich allgemein „zurückgezogen“, also [s̱], wobei der spanische Laut eher apikal ist, also [s̺], der griechische hingegen eher laminal, also [s̻]).
Zeichenzuordnungen der Laute und Lautzeichenerweiterungen
[Bearbeiten | Quelltext bearbeiten]Die IPA-Zeichentabelle nutzt unter anderem Buchstaben des lateinischen Schriftsystems und des griechischen Alphabets, teilweise in abgewandelter Form. Jedes Zeichen bezeichnet dabei einen Laut oder beschreibt einen bereits angegebenen Laut näher, der in einer Sprache der Welt ein Wort von einem anderen unterscheidet.
Das Internationale Phonetische Alphabet ist sprachenübergreifend; dies führt dazu, dass die Zuordnung eines Zeichens zu einem Laut in einer bestimmten Sprache nicht zwangsläufig mit der Lautzuordnung desselben Zeichens im IPA identisch ist. So steht beispielsweise das Zeichen [ç] im IPA für die Aussprache der Buchstabenfolge ch im deutschen Wort „ich“, obwohl es der deutschen Orthographie fremd ist; für die Abbildung der Aussprache des Französischen, dessen Orthografie „ç“ als stimmloses „s“ kennt, wird das Zeichen dagegen nicht benötigt.
Die Sonderzeichen des IPA-Alphabets wurden in Unicode im Bereich von U+0250 bis U+02AF aufgenommen.
Vokale
[Bearbeiten | Quelltext bearbeiten]Das IPA lässt sich in die Segmente Konsonant und Vokal aufteilen. Bei den Vokalen wird Höhe (hoch, mittel und tief), Stellung (vorne, Mitte und hinten) und Rundung (ungerundet und gerundet) unterschieden.[6]
| Vokale | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||||||||
| Bei Symbolpaaren (u • g) steht das linke Symbol für den ungerundeten, das rechte Symbol für den gerundeten Vokal. | ||||||||||||||||||
| vorn | fast vorn |
zentral | fast hinten |
hinten | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| ung. | ger. | ung. | ger. | ung. | ger. | ung. | ger. | ung. | ger. | |
| geschlossen | i | y | ɨ | ʉ | ɯ | u | ||||
| fast geschlossen | ɪ | ʏ | ʊ | |||||||
| halbgeschlossen | e | ø | ɘ | ɵ | ɤ | o | ||||
| mittel | e̞ | ø̞ | ə | o̞ | ||||||
| halboffen | ɛ | œ | ɜ | ɞ | ʌ | ɔ | ||||
| fast offen | æ | ɐ | ||||||||
| offen | a | ɶ | a̱ | ɑ | ɒ | |||||
Verweilt der Mauszeiger neben einem Zeichen in dessen Tabellenzelle, wird sein Unicode-Wert angezeigt; zeigt man auf das Zeichen, so erhält man eine kurze Beschreibung als Tooltip.
Konsonanten
[Bearbeiten | Quelltext bearbeiten]Das IPA lässt sich in die Segmente Konsonant und Vokal aufteilen. Die Konsonanten werden nach Stimmhaftigkeit (stimmhaft und stimmlos), Ort (bilabial, labio-dental, dental-alveolar, velar und glottal) und Art (nasal, plosiv und frikativ) unterschieden.[7] Bei den Konsonanten sind verschiedene Luftstrommechanismen zu unterscheiden.
Die pulmonalen Konsonanten werden mit ausströmender Atemluft (d. h. Luft aus der Lunge) erzeugt (pulmonal-egressiv). Zu dieser Gruppe zählen die allermeisten Konsonanten. Bei den Ejektiven und Implosiven wird der Luftstrom dagegen durch Bewegungen des Kehlkopfs erzeugt. Bei den Ejektiven bewegt sich der Kehlkopf nach oben, sodass Luft ausströmt (glottal-egressiv); bei den Implosiven bewegt er sich nach unten, sodass Luft einströmt (glottal-ingressiv). Schnalzlaute (manchmal auch als „Avulsive“ oder im Englischen als „clicks“ bezeichnet) entstehen dadurch, dass Zunge und Gaumensegel einen abgeschlossenen Hohlraum bilden, der durch eine Zurück- und Abwärtsbewegung der Zunge vergrößert wird. Beim Öffnen des Hohlraums findet ein Druckausgleich statt (Luft strömt hinein, daher velar-ingressiv), sodass ein Laut erzeugt wird.
Pulmonale Konsonanten
[Bearbeiten | Quelltext bearbeiten]| labial | koronal | dorsal | radikal | laryngal | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| bilabial | labiodental | linguo-
labial |
dental | alveolar | postalveolar | retroflex | alveolo-palatal | palatal | velar | uvular | pharyngal | epi-
glottal |
glottal | ||||||||||||||||||
| stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | stl. | sth. | ||||||
| Plosive | p | b | p̪ | b̪ | t̼ | d̼ | t̪ | d̪ | t | d | ʈ | ɖ | c | ɟ | k | g | q | ɢ | ʡ | ʔ | |||||||||||
| Semi-Plosive | p͡ɸ | b͡β | t̪͡θ | d̪͡ð | t͡s | d͡z | t͡ʃ | d͡ʒ | ʈ͡ʂ | ɖ͡ʐ | t͡ɕ | d͡ʑ | c͡ç | ɟ͡ʝ | k͡x | ɡ͡ɣ | q͡χ | ɢ͡ʁ | ʡ͡ʜ | ʔ͡h | |||||||||||
| Sibilante Frikative | s | z | ʃ | ʒ | ʂ | ʐ | ɕ | ʑ | |||||||||||||||||||||||
| Non-Sibilante Frikative | ɸ | β | f | v | θ̼ | ð̼ | θ | ð | θ̠ | ð̠ | ɹ̠̊˔ | ɹ̠˔ | ɻ̊˔ | ɻ˔ | ç | ʝ | x | ɣ | χ | ʁ | ħ | ʕ | ʜ | ʢ | h | ɦ | |||||
| laterale Semi-Plosive | t͡ɬ | d͡ɮ | |||||||||||||||||||||||||||||
| laterale Frikative | ɬ | ɮ | ꞎ | ɭ˔ | ʎ̥˔ | ʎ̝ | ʟ̝̊ | ʟ̝ | |||||||||||||||||||||||
| Nasale | m̥ | m | ɱ̊ | ɱ | n̼ | n̪ | n̥ | n | ɳ̊ | ɳ | ɲ̊ | ɲ | ŋ̊ | ŋ | ɴ̥ | ɴ | |||||||||||||||
| Vibranten | ʙ̥ | ʙ | r̪ | r̥ | r | ɽ̊r̥ | ɽr | ʀ̥ | ʀ | ||||||||||||||||||||||
| Taps/Flaps | ⱱ̟ | ⱱ | ɾ̼ | ɾ̥ | ɾ | ɽ̊ | ɽ | ɢ̆ | ʡ̆ | ||||||||||||||||||||||
| laterale Flaps | ɺ̥ | ɺ | 𝼈̥ | ɭ̆ | ʎ̆ | ʟ̆ | |||||||||||||||||||||||||
| Approximanten | ʋ | ɹ | ɻ | j | ɰ | ʔ̞ | |||||||||||||||||||||||||
| laterale Approximanten | l | ɭ | ʎ | ʟ | ʟ̠ | ||||||||||||||||||||||||||
Verweilt der Mauszeiger neben einem Zeichen in dessen Tabellenzelle, wird sein Unicode-Wert angezeigt; zeigt man auf das Zeichen, so erhält man eine kurze Beschreibung als Tooltip.
Gegebenenfalls steht jeweils links der stimmlose und rechts der stimmhafte Konsonant.
Dunkel hinterlegte Felder bezeichnen physiologisch unmögliche Artikulationen. Beispielsweise ist ein glottaler Nasal unmöglich, weil bei einem Verschluss der Stimmlippen keine Luft durch die Nase ausströmen kann usw.
Nicht-pulmonale Konsonanten
[Bearbeiten | Quelltext bearbeiten]
|
|
|
Andere Symbole
[Bearbeiten | Quelltext bearbeiten]| Zeichen | Unicode-Code | Bedeutung |
|---|---|---|
| ʍ | U+028D | stimmloser labiovelarer Frikativ |
| w | U+0077 (w) | stimmhafter labiovelarer Approximant |
| ɥ | U+0265 | stimmhafter labiopalataler Approximant |
| ʜ | U+029C | stimmloser epiglottaler Frikativ |
| ʢ | U+02A2 | stimmhafter epiglottaler Frikativ |
| ʡ | U+02A1 | stimmloser epiglottaler Plosiv |
| ɺ | U+027A | stimmhafter lateraler alveolarer Flap |
| ɧ | U+0267 | stimmloser velopalataler Frikativ ([ʃ] und [x] zugleich) |
Suprasegmentalia
[Bearbeiten | Quelltext bearbeiten]Von den suprasegmentalen Zeichen stehen die Betonungszeichen vor der Silbe, auf die sie sich beziehen, die Längezeichen danach.
| Zeichen | Unicode-Code | Bedeutung | Beispiele |
|---|---|---|---|
| ˈ (kein Apostroph) | U+02C8 | Hauptbetonung | April [], Backe [] |
| ˌ (kein Komma) | U+02CC | Nebenbetonung | Wasserpfeife [], Ringelblume [] |
| ː (kein Doppelpunkt) | U+02D0 | lang | Lack [], lag [] |
| ˑ | U+02D1 | halblang | Bier [] (oft bei Tiefschwas) |
| ˘ | U+0306 | extrakurz | Studium [] |
| . | U+002E (.) | Silbengrenze | Bo-te [], Mu-se-um [] |
| U+007C (|) | untergeordnete Intonationsgruppe (Sprechtaktgrenze) | Sie haben Glück, nicht wahr? [] | |
| ‖ | U+2016 | übergeordnete Intonationsgruppe | |
| U+035C oder U+0361 | Doppelartikulation | schwarz [] oder [] |
Töne und Intonation
[Bearbeiten | Quelltext bearbeiten]| Zeichen | Unicode-Code | Bedeutung | Beispiele |
|---|---|---|---|
| (Doppelakut) oder ˥ | U+030B oder U+02E5 | besonders hoch | [] |
| (Akut) oder ˦ | U+0301 oder U+02E6 | hoch | [é] |
| (Makron) oder ˧ | U+0304 oder U+02E7 | mittel | [ē] |
| (Gravis) oder ˨ | U+0300 oder U+02E8 | niedrig | [è] |
| (Doppelgravis) oder ˩ | U+030F oder U+02E9 | besonders niedrig | [ȅ] |
| (Hatschek) | U+030C | steigend | [ě] |
| (Zirkumflex) | U+0302 | fallend | [ê] |
| U+A71C | stufenweise abwärts / downstep | ||
| U+A71B | stufenweise aufwärts / upstep | ||
| U+2197 | Generalanstieg / global rise | ||
| U+2198 | Generalabfall / global fall |
Bemerkung:
- Unicode hat keine eigenen Zeichen für die meisten Konturtöne. Stattdessen werden Folgen aus Zeichen für Registertöne verwendet und die genaue Darstellung wird der jeweiligen Schriftart überlassen, üblicherweise durch OpenType-Regeln: [] oder [] (in vielen Browsern nicht korrekt dargestellt). Weil nur sehr wenige Schriftarten die Kombinierung von Registerton-Zeichen erlauben, wird oft das alte System der Tonmarkierung durch hochgestellte Nummern von „1“ bis „5“ verwendet, beispielsweise [e53 e312]. Deren Verwendung hängt allerdings von lokalen Linguistiktraditionen ab; bei asiatischen Sprachen wird „5“ für den höchsten Ton verwendet und „1“ für den tiefsten, bei den afrikanischen Sprachen umgekehrt. Gelegentlich ist noch eine alte IPA-Tradition anzutreffen, nach der die Konturtöne durch untergesetzte Diakritika bezeichnet werden: [] für tief-fallend bzw. tief-steigend.
Diakritika
[Bearbeiten | Quelltext bearbeiten]Diakritika werden für phonetische Details verwendet. Sie ergänzen IPA-Zeichen und bezeichnen die Modifikation oder Spezifikation der normalen Aussprache eines Zeichens.[8]
| Zeichen | Unicode-Code | Bedeutung | Beispiele |
|---|---|---|---|
| Phonation (Siehe auch Anmerkung am Ende der Tabelle) | |||
| untergestellt: | U+0325 |
stimmlos, bzw. entstimmt |
See [] (südliches Deutsch) |
| übergestellt: | U+030A | gut [] (südliches Deutsch) | |
| untergestellt: | U+032C |
stimmhaft |
[], [] |
| übergestellt: | U+030C | [ǧ] | |
| übergestellt: | U+02B0 | aspiriert | Tasse [], [] |
| Genauere Beschreibung der Artikulation eines Vokals | |||
| untergestellt: | U+0339 | stärker gerundet | [] |
| übergestellt: | U+0357 | ||
| untergestellt: | U+031C | weniger gerundet | [] |
| übergestellt: | U+0351 | ||
| U+031F | weiter vorne | [] | |
| U+0320 | weiter hinten | [] | |
| U+0308 | zentralisiert | [ë] | |
| U+033D | zur Mitte zentralisiert | [] | |
| U+031D | angehoben | [] | |
| U+031E | gesenkt | [] | |
| U+0318 | vorverlagerte Zungenwurzel | [] | |
| U+0319 | zurückverlagerte Zungenwurzel | [] | |
| U+02DE | rhotisch | [ɚ] | |
| Genauere Beschreibung des artikulierenden Organs bei Konsonanten | |||
| untergestellt: | U+032A | dental | [], [], [], [] |
| übergestellt: | U+0346 | ||
| U+033C | linguolabial | [], [] | |
| U+033A | apikal | [], [] | |
| U+033B | laminal | [], [] | |
| U+0303 | nasaliert | Chance [] | |
| Zusätzliche Engebildung | |||
| ʷ | U+02B7 | labialisiert | Glück [] |
| ʲ | U+02B2 | palatalisiert | [], [] |
| ˠ | U+02E0 | velarisiert | [], [] |
| ˁ | U+02C1 | pharyngalisiert | [], [] |
|
|
U+0334 | velarisiert oder pharyngalisiert | [ɫ] |
| ˀ | U+02C0 | glottalisiert | |
| Art der Verschlusslösung für Plosive | |||
| ⁿ | U+207F | nasale Verschlusslösung | Redner [] |
| ˡ | U+02E1 | laterale Verschlusslösung | Handlung [] |
| U+031A | keine hörbare Verschlusslösung | stimmt [] | |
| Silbizität | |||
| untergestellt: | U+0329 | silbisch | reden [] |
| übergestellt: | U+030D | Regen [] | |
| untergestellt: | U+032F | nichtsilbisch | aktuell [] Libyen [] |
| übergestellt: | U+0311 | ||
| Stimmqualität | |||
| untergestellt: | U+0324 | behaucht | [], [] |
| übergestellt: | U+0308 | ||
| untergestellt: | U+0330 | knarrig | [], [] |
| übergestellt: | U+0303 | ||
Anmerkung: Ob mit Diakritika versehene Zeichen Äquivalente zu dem jeweils anderen Zeichen der Artikulationsart und des Artikulationsortes sind, ist von der IPA nicht vollständig festgelegt worden. Im „Handbuch der International Phonetic Association“ heißt es dazu: „Es ist strittig, ob [] und [g] phonetisch identische Laute bezeichnen, und dasselbe gilt für [s] und []. Möglicherweise werden bei der Unterscheidung zwischen [] und [g] oder [s] und [] unterschiedliche Dimensionen einbezogen, die von der Stimmbandvibration unabhängig sind, wie etwa Gespanntheit gegenüber Ungespanntheit in der Artikulation, sodass die Möglichkeit, Stimmhaftigkeit separat zu bezeichnen, wichtig wird. Es kann aber in jedem Fall vorteilhaft sein, wenn man in der Lage ist, die lexikalische Form eines Wortes beizubehalten […].“
Zeichen mit Unterlänge können durch ein übergestelltes Diakritikum ausgezeichnet werden. Standardmäßig sollte jedoch mit untergestellten Diakritika ausgezeichnet werden, wenn beide Möglichkeiten bestehen.
Alternative Notationen
[Bearbeiten | Quelltext bearbeiten]Ältere Notationen
[Bearbeiten | Quelltext bearbeiten]Das IPA ist nicht das einzige System zur Notation von Sprachlauten. Im Laufe der Zeit hat es einige Versuche gegeben, Laute exakter darzustellen als in herkömmlicher Rechtschreibung. Schon 1855 veröffentlichte der deutsche Ägyptologe Karl Richard Lepsius sein Standardalphabet „zur Darstellung ungeschriebener Sprachen und fremder Zeichensysteme in einer einheitlichen Orthographie in europäischen Buchstaben“. Überarbeitet erschien das Werk 1863 außer auf Deutsch auch auf Englisch. Zeitgenössische Texte über die Laute der menschlichen Sprache belegen, dass dieses Standardalphabet als Lautschrift aufgefasst wurde. Einige seiner Zeichen sind in das IPA-Alphabet eingegangen. Für deutsche Transliterationen (also Wiedergaben der Schreibung) wurde seine an der tschechischen Orthographie orientierte Unterscheidung verschieden artikulierter Zischlaute übernommen, nicht aber in die IPA-Lautschrift.
Alexander Melville Bell stellte demgegenüber 1867 in seinem System der Visible Speech eine ikonische Notation vor, bei der einzelne Merkmale eines Lautes (z. B. die Rundung der Lippen und dergleichen) im Zeichen selbst abgebildet werden. Andere Versuche in Richtung einer analphabetischen Notation wurden von den Linguisten Otto Jespersen (1889) oder Kenneth L. Pike (1943) unternommen. Dadurch, dass in diesen Systemen die einzelnen Stellungen der Sprechwerkzeuge unabhängig voneinander angegeben werden können, lassen sich Lautnuancen viel feiner kodieren.
Heute noch verwendete Systeme
[Bearbeiten | Quelltext bearbeiten]In der deutschen und romanistischen Dialektologie ist zum Teil auch heute noch die Teuthonista-Transkription üblich. Die Teuthonista ist 1924/25 von Hermann Teuchert in der dialektologischen Zeitschrift Teuthonista präsentiert worden und baut mit einem Bezug auf Karl Richard Lepsius’ Standardalphabet im Wesentlichen auf dem lateinischen Alphabet auf. Da ähnliche Vorschläge in der Romania von Graziadio Isaia Ascoli und Eduard Böhmer vorgestellt worden sind, sind die Teuthonista- und die Böhmer-Ascoli-Transkription heute weitgehend zusammengefallen.
In Italien spielte IPA bis in die 1960er Jahre kaum eine Rolle.[9] Luciano Canepari entwickelte auf Grundlage der IPA eine eigene Lautschrift mit einer deutlich größeren Anzahl an Zeichen,[9] auch für Intonationsmuster, die allerdings kaum Verbreitung gefunden hat.[10]
IPA in Sprachtechnologie und Internet: SAMPA, X-SAMPA und Kirshenbaum
[Bearbeiten | Quelltext bearbeiten]Mit den Notationen SAMPA (für 7 europäische Sprachen) und X-SAMPA (die SAMPA-Erweiterung für das vollständige IPA) wurden von europäischen Phonetikern und Sprachingenieuren im Rahmen von multilingualen sprachtechnologischen EU-Forschungsprojekten in den 1980er Jahren Alphabete entwickelt, mittels derer IPA-Zeichen im ASCII-Code geschrieben werden konnten. Diese Notationen, die in der Sprachtechnologie sehr verbreitet sind, dienen folgenden Zwecken:
- Austausch phonetischer Daten (Transkriptionsdateien und Sprachsignal-Annotationsdateien) in einfacher Textform.
- Einfache programmiertechnische Verarbeitung von Transkriptionen in der automatischen Spracherkennung und in der Sprachsynthese.
- Einfache Überprüfung und Redaktion phonetischer Daten bei gleichzeitiger maschineller Lesbarkeit.
- Tastaturfreundliche Eingabe aller mit dem IPA darstellbaren Laute.
Diese Notationen wurden nicht für die allgemeine Darstellung des IPA in Veröffentlichungen entworfen, werden aber häufig in technisch-wissenschaftlichen Veröffentlichungen zur Datendarstellung verwendet. Für allgemeine Veröffentlichungszwecke, auch im Internet, sind standardisierte Unicode-Zeichensätze, die eher Text-Ausgabe- als -Eingabe-orientiert sind, besser geeignet.
Unabhängig von SAMPA und X-SAMPA wurde von Internetznutzern in den frühen 1990er Jahren das ähnliche Kirshenbaum-Alphabet entwickelt, das sich jedoch nicht durchsetzen konnte. In den USA werden vorwiegend für die englische Sprache häufig das „Klattbet“ oder das „Arpabet“ in der Sprachtechnologie verwendet.
Siehe auch
[Bearbeiten | Quelltext bearbeiten]- IPA Braille
- Liste ehemaliger IPA-Zeichen
- Uralisches Phonetisches Alphabet
- Nichtpulmonaler Laut
- Intonation (Phonetik)
Literatur
[Bearbeiten | Quelltext bearbeiten]- Handbook of the International Phonetic Association.A guide to the use of the International Phonetic Alphabet. Cambridge University Press, 1999, ISBN 978-0-521-65236-0.
- M. Duckworth, G. Allen, W. Hardcastle, M. J. Ball: Extensions to the International Phonetic Alphabet for the transcription of atypical speech. In: Clinical Linguistics and Phonetics. Band 4, 1990, S. 273–280.
- J. Alan Kemp: The history and development of a universal phonetic alphabet in the 19th century. From the beginnings to the establishment of the IPA. In: Sylvain Auroux, E. F. K. Koerner, Hans-Josef Niederehe, Kees Versteegh (Hrsg.): History of the Language Sciences. Geschichte der Sprachwissenschaften. Histoire des sciences du langage. Walter de Gruyter, Berlin / New York 2001, ISBN 3-11-016735-2, S. 1572–1584.
- William A. Ladusaw, Geoffrey Pullum: Phonetic Symbol Guide. University of Chicago Press, 1996, ISBN 0-226-68535-7.
- George A. Miller: Wörter. Streifzüge durch die Psycholinguistik. Herausgegeben und aus dem Amerikanischen übersetzt von Joachim Grabowski und Christiane Fellbaum. Spektrum der Wissenschaft, Heidelberg 1993; Lizenzausgabe: Zweitausendeins, Frankfurt am Main 1995; 2. Auflage ebenda 1996, ISBN 3-86150-115-5, S. 72–78, insbesondere S. 76 ff.
Weblinks
[Bearbeiten | Quelltext bearbeiten]- IPA Trainer Online Applikation zum Üben von Phonetik und Transkription (Seite nicht mehr abrufbar, festgestellt im August 2019. Suche in Webarchiven)
- Website der International Phonetic Association
- IPA Charts – interaktive Darstellung der Laute
- The Unicode Standard 5.0, Section 7.1: IPA Extensions: U+0250-U+02AF (PDF-Datei; 670 kB)
- The Unicode Standard 5.0, Section 7.1: Spacing Modifier Letters: U+02B0-U+02FF (PDF-Datei; 670 kB)
- The Unicode Standard 5.0, Code Chart IPA Extensions (PDF; 310 kB)
- The Unicode Standard 5.0, Code Chart Spacing Modifier Letters (PDF; 236 kB)
- The Unicode Standard 5.0, Code Chart Superscripts and Subscripts (PDF-Datei; 69 kB)
- IPA-Tabelle mit Tonaufnahmen vom Phonetischen Laboratorium der Universität Turin, Italien
- Vorlesen der IPA-Tabelle mit Ausnahme der epiglottalen Konsonanten (YouTube-Video)
- Texte aus IPA-Symbolen interaktiv zusammenstellen
- IPA-Reader: Liest IPA-Text in verschiedenen Sprachen vor
Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ vgl. P. T. Daniels, W. Bright (Hrsg.): The World’s Writing Systems. New York / Oxford 1996, S. 821–846.
- ↑ History of the IPA, abgerufen am 19. August 2016
- ↑ George A. Miller: Wörter. Streifzüge durch die Psycholinguistik. Herausgegeben und aus dem Amerikanischen übersetzt von Joachim Grabowski und Christiane Fellbaum. Spektrum der Wissenschaft, Heidelberg 1993; Lizenzausgabe: Zweitausendeins, Frankfurt am Main 1995; 2. Auflage ebenda 1996, ISBN 3-86150-115-5, S. 76 und 303.
- ↑ John Esling: Computer Coding of the IPA: Supplementary Report. In: Journal of the International Phonetic Association. Band 20, 1990, Nr. 1.
- ↑ K.-H. Ramers: Phonologie. In: J. Meibauer [u. a.] (Hrsg.): Einführung in die germanistische Linguistik. Metzler, Stuttgart 2002, S. 70–120.
- ↑ George A. Miller: Wörter. Streifzüge durch die Psycholinguistik. 1996, S. 77.
- ↑ George A. Miller: Wörter. Streifzüge durch die Psycholinguistik. 1996, S. 77.
- ↑ International Phonetic Association: Handbook, Seiten 14–15.
- ↑ a b Andreas Michel: Einführung in die italienische Sprachwissenschaft. De Gruyter, 2016; S. 77.
- ↑ Matthias Heinz, Stephan Schmid: Phonetik und Phonologie des Italienischen. Eine Einführung für Studierende der Romanistik. De Gruyter, 2021, S. 248.