Skew Heap
Ein Skew Heap (oder selbst-balancierender Heap) ist in der Informatik eine als Binärbaum implementierte Heap-Datenstruktur. Skew Heaps können im Vergleich zu Binären Heaps schneller miteinander verschmolzen werden (merge). Sie haben allerdings keine strukturellen Einschränkungen, wodurch die Höhe des Baumes, also die größte Anzahl an miteinander verbundenen Knoten, nicht mehr gezwungenermaßen kleiner ist als der Logarithmus der Gesamtzahl der Knoten.
Eine Implementierung eines Skew Heaps muss zwei Bedingungen erfüllen:
- Die in den Skew Heap zu speichernden Daten benötigen eine Ordnung.
- Jede Operation auf einem oder zwei Skew Heaps (z. B. das Hinzufügen oder Entfernen von Knoten) muss mittels einer Verschmelzung der Skew Heaps durchgeführt werden.
Mittels amortisierter Laufzeitanalyse kann gezeigt werden, dass alle Operationen auf einem Skew Heap mit einer algorithmischen Komplexität von durchgeführt werden können.[1][2]

Definition
[Bearbeiten | Quelltext bearbeiten]Skew Heaps können rekursiv definiert werden:
- Ein Heap mit nur einem Element ist ein Skew Heap.
- Das Resultat der Verschmelzungsoperation (merge) zweier Skew Heaps ist ebenfalls ein Skew Heap.
- Die Verschmelzungsoperation ist definiert.
Operationen
[Bearbeiten | Quelltext bearbeiten]Rekursive Verschmelzung zweier Heaps (recursive merge)
[Bearbeiten | Quelltext bearbeiten]Die rekursive Verschmelzung zweier Skew Heaps ist ähnlich der Verschmelzung zweier Linksheaps:
- Gegeben seien zwei Heaps p und q, wobei die Wurzel von p kleiner sei als die von q. Der verschmolzene Baum sei r.
- Die Wurzel von p wird Wurzel von r.
- Der linke Teilbaum aus p wird der rechte Teilbaum in r.
- Der rechte Teilbaum aus p wird mit q rekursiv verschmolzen. Das Ergebnis wird zum linken Teilbaum in r
- Die Verschmelzung ist abgeschlossen, wenn in den Teilbäumen keine Knoten mehr übrig sind.
-
 Zwei Skew-Heaps. Die Wurzel des linken Heaps (1) ist kleiner als die des rechten (13).
Zwei Skew-Heaps. Die Wurzel des linken Heaps (1) ist kleiner als die des rechten (13).

-
 Das Ergebnis der Verschmelzung
Das Ergebnis der Verschmelzung

Nicht-rekursive Verschmelzung zweier Heaps (non-recursive merge)
[Bearbeiten | Quelltext bearbeiten]Alternativ zur rekursiven Verschmelzung zweier Skew Heaps existiert ein nicht-rekursiver Algorithmus, der allerdings eine Sortierung vor der eigentlichen Verschmelzung benötigt.
- Teile beide Skew Heaps in Teilbäume auf, indem der jeweils rechte Teilbaum von der Wurzel abgetrennt und zu einem eigenständigen Baum gemacht wird.
- Wiederhole Schritt 1 für alle abgetrennten Teilbäume, bis jede Wurzel jedes neuen Baumes nur noch einen linken Teilbaum besitzt. Das Ergebnis ist ein Set aus Bäumen, die entweder einen linken oder gar keinen Teilbaum besitzen.
- Sortiere die entstandene Menge aus Bäumen aufsteigend nach den Schlüsseln der Wurzeln.
- Kombiniere die letzten zwei Bäume der sortierten Menge (von rechts nach links) nach dieser Regel:
- Wenn die Wurzel des vorletzten Baumes einen linken Teilbaum besitzt, mache ihn zum rechten Teilbaum.
- Setze die Wurzel des letzten Baumes als den linken Teilbaum des vorletzten Baumes.
- Wiederhole den letzten Schritt, bis nur noch ein Baum übrig ist.
-
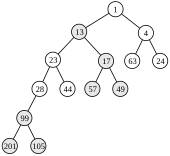
Ausgangssituation
-
 Teilung und Sortierung der Skew Heaps
Teilung und Sortierung der Skew Heaps -
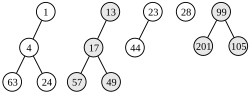 1. Kombination der letzten zwei Bäume
1. Kombination der letzten zwei Bäume -
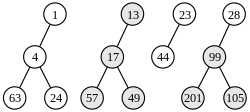 2. Kombination der letzten zwei Bäume
2. Kombination der letzten zwei Bäume



-
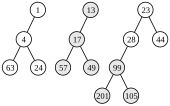 3. Kombination der letzten zwei Bäume
3. Kombination der letzten zwei Bäume -
 4. Kombination der letzten zwei Bäume mit Vertauschung der Teilbäume
4. Kombination der letzten zwei Bäume mit Vertauschung der Teilbäume -
5. Kombination und Ergebnis


Knoten hinzufügen (add)
[Bearbeiten | Quelltext bearbeiten]Das Hinzufügen eines Knotens zu einem bestehenden Skew Heap erfolgt mittels Verschmelzung. Der neue Knoten wird als eigenständiger Heap betrachtet und mit dem bestehenden verschmolzen.
Knoten mit dem kleinsten Wert entfernen (Remove_min bzw. extract_min)
[Bearbeiten | Quelltext bearbeiten]Die Wurzel eines Skew Heaps ist zwingend der Knoten mit kleinsten Wert und kann so einfach abgefragt werden. Der kleinste Knoten wird entfernt, indem die beiden entstehenden Teilbäume miteinander verschmolzen werden.
Implementierung
[Bearbeiten | Quelltext bearbeiten]In vielen funktionalen Programmiersprachen können Skew Heaps sehr simpel implementiert werden. Folgend ein Beispiel für eine Implementierung in Haskell.
data SkewHeap a = Empty
| Node a (SkewHeap a) (SkewHeap a)
singleton :: Ord a => a -> SkewHeap a
singleton x = Node x Empty Empty
union :: Ord a => SkewHeap a -> SkewHeap a -> SkewHeap a
Empty `union` t2 = t2
t1 `union` Empty = t1
t1@(Node x1 l1 r1) `union` t2@(Node x2 l2 r2)
| x1 <= x2 = Node x1 (t2 `union` r1) l1
| otherwise = Node x2 (t1 `union` r2) l2
insert :: Ord a => a -> SkewHeap a -> SkewHeap a
insert x heap = singleton x `union` heap
extractMin :: Ord a => SkewHeap a -> Maybe (a, SkewHeap a)
extractMin Empty = Nothing
extractMin (Node x l r) = Just (x, l `union` r)
Literatur
[Bearbeiten | Quelltext bearbeiten]- Marc Guyomard: The Teaching of Data Structures!: A Balanced Presentation of Skew Heaps. In: The B method: from Research to Teaching, 2010, S. 45–64. HAL: inria-00594112, version 1
- Chris Okasaki Fun with binary heap trees. In The fun of Programming, 2003, ISBN 1-4039-0772-2, ISBN 0-333-99285-7, S. 1–16.
Einzelnachweise
[Bearbeiten | Quelltext bearbeiten]- ↑ Daniel Dominic Sleator, Robert Endre Tarjan: Self-Adjusting Heaps. In: SIAM Journal on Computing, 15 (1), 1986, S. 52–69. doi:10.1137/0215004, ISSN 0097-5397.
- ↑ Berry Schoenmakers: A Tight Lower Bound for Top-Down Skew Heaps. In Information processing letters, 61, no. 5, 14. März 1997, S. 279–284, ISSN 0020-0190.