Diskussion:Adygeische Sprache
Knacklaute
[Quelltext bearbeiten]Was ist das denn für ein Quatsch? Knacklaute gibts im Adyge ganz sicher nicht (es gibt ja nur einen!). Wahrscheinlich meint ihr die Ejektive. Und: Was bitte soll palativ sein????? Palatal gibt es, vielleicht meint ihr das? Bitte dringendst um Korrektur. Habe daher Überarbeiten-Baustein eingesetzt. Informiert euch bitte, was ein Knacklaut ist. Viele Grüße, --Thomas Goldammer (Disk.) 00:38, 11. Mär 2006 (CET)
- Hat sich erledigt. Ich konnte den Artikel nicht mehr sehen und habe ihn selbst überarbeitet. ;-) Also nochmal Grüße, --Thomas Goldammer (Disk.) 01:40, 11. Mär 2006 (CET)
Überarbeitung der Alphabet-Übersicht
[Quelltext bearbeiten]Aus einer Frage an WajWohu heraus, in der es um eine Ersatzschreibung der Palotschka ging, hat sich eine allgemeinere Diskussion entwickelt, deren Teile, die sich auf den Artikel zur adygeischen Sprache beziehen, folgend übertragen sind, wo sie besser hinpassen (Änderungen 234646864 bis 234703766, Diskussion zum Zeitpunkt des Übertrags). — Speravir – 00:05, 21. Jun. 2023 (CEST)
Hallo, zu dieser Änderung: Einerseits höchst interessant, war mir noch nicht bewusst (ich hab das immer für das kyrillische І gehalten). Aber das zitierte YouTube-Video nutzt nun einmal den Ersatz. Wäre es vielleicht besser, die 1 wieder einzufügen und dafür im Kommentar darauf hinzuweisen, dass es sich um eine Ersatzschreibung handelt? Wäre nicht im Abschnitt zum Alphabet auch eine kurze Erwähnung der im Artikel bisher überhaupt nicht aufgeführten Palotschka und mutmaßlich weiterer Hilfszeichen sinnvoll? — Speravir – 02:52, 16. Jun. 2023 (CEST)
- @Speravir: Natürlich, das könnte man auch machen. Vielleicht eine Anmerkungs-Fußnote an das Palotschka in der Buchstaben-Tabelle? Es ist das vorletzte Zeichen im Alphabet (rechts unten). Grüße--WajWohu (Diskussion) 08:52, 16. Jun. 2023 (CEST)
- Als Erstes: Ach, Du Sch…, dass ich das übersehen habe, also nix mit nicht aufgeführt. Aber ansonsten: Ja, das wäre wohl eine gute Lösung, auch für die anderen, die anscheinend ebenso als Hilfszeichen dienen. Mir geht es ja nicht allein um die Ersatzzeichennutzung. Du hattest
irgendwo(*) entsprechende Ausführungen gemacht, die meiner Meinung nach in den Artikel übernommen werden sollten. Interessanterweise haben К к, КІ кІ und О о schon Sternchen angehängt, aber es fehlen die offensichtlich dafür gedachten Anmerkungen. — Speravir – 00:52, 17. Jun. 2023 (CEST) - (*) Nachtrag: Nicht irgendwo, sondern in der QS zu Tighudschiqo Qizbetsch (Spezial:Diff/234597291/234605376). — Speravir – 01:31, 17. Jun. 2023 (CEST)
- Als Erstes: Ach, Du Sch…, dass ich das übersehen habe, also nix mit nicht aufgeführt. Aber ansonsten: Ja, das wäre wohl eine gute Lösung, auch für die anderen, die anscheinend ebenso als Hilfszeichen dienen. Mir geht es ja nicht allein um die Ersatzzeichennutzung. Du hattest
- Oha, mir fiel gerade eben noch etwas anderes auf: Die IPA-Ausprachehinweise in der Einleitung und in der Infobox sind unterschiedlich. — Speravir – 01:37, 17. Jun. 2023 (CEST)
[…] Palotschka […] oder ist es doch das kyrillische I? In der Tabelle des adygeischen wird letzteres übrigens überall genutzt außer an der Stelle, wo (laut dir ![]() ) die Palotschka stehen soll – dort wurde das lateinische I eingesetzt. — Speravir – 01:59, 17. Jun. 2023 (CEST)
) die Palotschka stehen soll – dort wurde das lateinische I eingesetzt. — Speravir – 01:59, 17. Jun. 2023 (CEST)
- Hui, :) Also, die Tabelle mit den Sternchen aber fehlenden Anmerkungen ist nicht nur in unserem Artikel Adygeische Sprache, sondern auch im russ. Interwiki, die wird wohl aus irgendeinem Interwiki übernommen sein, dabei aber die Anmerkungen übersehen worden sein. Siehst du, aus welchem Interwiki sie kommt?
- Ich sehe gerade, dass in en:WP eine zweite Tabelle mit IPA-Zeichen und Aussprache-Audio drin ist, sicher auch eine gute Lösung, das zu übernehmen? Die Sprache ist eben phonetisch sehr ungewöhnlich/fremd für Leser. Man kann es ja nochmal mit dem sehr sorgfältig ausgearbeiteten Video vergleichen.
- Das große I gibt es generell nicht im Adygeischen, oder irgendeiner anderen kaukasischen Sprache, auch nicht im Russischen, das kenne ich nur aus dem Ukrainischen, wo es ein Großbuchstabe ist. Da muss also immer das Palotschka stehen. In der Tabelle überall auch in Kombinationen, ich sehe schlecht optisch, ob da irgendwov das minimal längere große I fälschlich steht, muss man wohl die Quellcodes vgl. Auch im Geschlechtername ШэрэлIыкъо muss da ein Palotschka stehen. Das ist übrigens das Zeichen, das im Video min. 2:53 ausgesprochen wird und ähnlich einem stimmlosen, ejektiven (gestoßenen) "tl" klingt.
- Ja die IPA der Selbstbezeichnung der Sprache ist verschieden, die in der Einleitung scheint deutlich besser. Hab es jetzt gerade nicht Phonem für Phonem verglichen (betreue gerade meine lebhaften Kleinkinder). Grüße--WajWohu (Diskussion) 07:57, 17. Jun. 2023 (CEST)
- Wie können diese Rangen nur?
 Im Ernst: Sowas geht natürlich vor!
Im Ernst: Sowas geht natürlich vor! - Zu der Tabelle müsste ich auch erst mal nachforschen. Mal sehen.
- Zu IPA: Wenn Du die Ausführungen im Enwiki für plausibel hältst, dann immer herüber damit. In der Infobox werde ich es entfernen, die Boxen für andere kaukasische Sprachen haben das auch nicht.
- Bei der von mir verwendeten Schrift sehen alle drei Buchstaben sogar identisch aus, da musst Du dir keine Sorgen wegen Sehproblemen machen. (Laut Artikel hat die Palotschka eine Kleinbuchstabenvariante, auch wenn sie anscheinend im Adygeischen nicht genutzt wird. Jedenfalls wird sie in der von mir genutzten Schrift wie ein kleines l dargestellt, aber die Schrift im Editor stellt Groß- und Kleinbuchstabe identisch in der Glyphe des Großbuchstaben dar! Übrigens sind auch hier alle drei Großbuchstaben identisch in der Darstellung.)
- Ich werde gleich, nachdem ich das hier geschrieben habe, […] alles zur Palotschka hin korrigieren.
- — Speravir – 23:24, 17. Jun. 2023 (CEST)
- Hallo Speravir, Hier ist Georgij A. Klimov: "Einführung in die kaukasische Sprachwissenschaft." übersetzt von dem Indogermanisten und Kaukasiologen Jost Gippert. Auf S. 390 ff. finden sich Transkriptionstabellen der kyrillischen Buchstaben, welche Laute sie in den verschiedenen kaukasischen Sprachen umschreiben-erst kommen die verschiedenen Konsonantenklassen, dass die Vokale, schließlich noch für Georgisch und Armenisch, die eigene Schriften haben (Armenisch ist eigentlich eine indoeuropäische/indogermanische Sprache, keine kaukasische). Schau die Tabellen zu der Frage der IPA-Umschrift bitte einmal genau an. Die erste Spalte ist die "wissenschaftliche Transkription", die zweite Spalte die IPA-Zeichen. Nicht in allen kaukasischen Spr. bezeichnet derselbe kyrill. Buchstabe denselben Laut, deshalb ist das wie eine Zuordnungstabelle aufgebaut, Adygeisch ist die 5. Spalte. Im Einführungssatz ist die IPA-Umschift, über der Box steht die wiss. Transkription. Ich korrigiere die IPA gleich nochmal an 2 Feinheiten, muss dann aber aufhören, weil die Kleinen morgen 6:00 Uhr weiter machen :) Schau bitte nochmal rein, ob ich etwas übersehen habe, müsste jetzt beides stimmen. Grüße.--WajWohu (Diskussion) 23:55, 17. Jun. 2023 (CEST)
- Die Tabelle mit Hörproben der Laute aus en:WP fände ich bei dieser phonetisch ungewöhnlichen Sprache ziemlich passend, ist ja in dem Video auch überprüfbar. Grüße--WajWohu (Diskussion) 08:07, 18. Jun. 2023 (CEST)
- Hallo Speravir, Hier ist Georgij A. Klimov: "Einführung in die kaukasische Sprachwissenschaft." übersetzt von dem Indogermanisten und Kaukasiologen Jost Gippert. Auf S. 390 ff. finden sich Transkriptionstabellen der kyrillischen Buchstaben, welche Laute sie in den verschiedenen kaukasischen Sprachen umschreiben-erst kommen die verschiedenen Konsonantenklassen, dass die Vokale, schließlich noch für Georgisch und Armenisch, die eigene Schriften haben (Armenisch ist eigentlich eine indoeuropäische/indogermanische Sprache, keine kaukasische). Schau die Tabellen zu der Frage der IPA-Umschrift bitte einmal genau an. Die erste Spalte ist die "wissenschaftliche Transkription", die zweite Spalte die IPA-Zeichen. Nicht in allen kaukasischen Spr. bezeichnet derselbe kyrill. Buchstabe denselben Laut, deshalb ist das wie eine Zuordnungstabelle aufgebaut, Adygeisch ist die 5. Spalte. Im Einführungssatz ist die IPA-Umschift, über der Box steht die wiss. Transkription. Ich korrigiere die IPA gleich nochmal an 2 Feinheiten, muss dann aber aufhören, weil die Kleinen morgen 6:00 Uhr weiter machen :) Schau bitte nochmal rein, ob ich etwas übersehen habe, müsste jetzt beides stimmen. Grüße.--WajWohu (Diskussion) 23:55, 17. Jun. 2023 (CEST)
- Wie können diese Rangen nur?
Übertrag Ende. Einiges Angesprochene wurde bereits geändert. Antwort auf die letzte Meldung:
Dachte ich mir auch. Ich könnte es rein technisch gesehen übernehmen, diese ausführliche Tabelle in den Artikel einzubauen (ich würde aber die Beispiele weglassen, ich sehe da keinen Nutzen; die Sternchen werden gleich mitentfernt, denn auf keiner einzigen Seite findet sich eine Erklärung), es wäre dann aber sehr, sehr sinnvoll, wenn Du das danach kontrollieren würdest, WajWohu. Über die dort genannte Quelle Transliteration of Agyghe fand ich übrigens ein Dokument von J. Gippert, das Du als Anhang des Klimov-Werkes (mit J. Gippert als Bearbeiter) zitiert hast: Caucasian alphabet systems based upon the Cyrillic script. Was außerdem bisher fehlt, sind die historisch verwendeten lateinischen und arabischen Alphabete, das würde ich gleichfalls übernehmen. Was hältst von der kürzeren Tabelle unter en:Adyghe language#Phonology (bzw. einem eigenen Abschnitt zur Phonologie, wo Du die Besonderheiten kurz ausführen könntest) und von Datei:WIKITONGUES- Yenal speaking Circassian.webm (beachte Beschreibung)? — Speravir – 00:05, 21. Jun. 2023 (CEST)
(Alles zur Palotschka von unten nach oben verschoben — Speravir – 01:36, 24. Jun. 2023 (CEST))
---8<---Schnipp---8<---
Hier egtl. OT, weil allgemeine Frage: wie heißt die "Palotschka" eigentlich auf "Nicht-Russisch"?! ZB sogar der tschetschenische WP-Artikel (vielmehr Stub) hilft da nicht wirklich weiter, wenn ich ihn richtig "verstehe"... --AMGA 🇺🇦 (d) 13:18, 22. Jun. 2023 (CEST)
- Das weiß ich nicht. Mit Sicherheit wurde es mit der Latinisierung in der Sowjetunion Ende der 20er Jahre von russischsprachigen Linguisten entworfen und benannt, denn in der lateinschriftlichen Variante existiert es bereits. Sicher gibt es da Entlehnungen, Übersetzungen oder auch Neubenennungen in einigen kaukasischen Sprachen. Das Interwiki ce:Ӏ (элп) nutzt wirklich nicht viel, denn wenn man das "элп" in Klammern in dieses Tschtschenisch-Russ.-Tschetschenisch WB eingibt (Suchergebnisse lassen sich nicht anzeigen), heißt das einfach nur "Buchstabe". Gibt man dort aber "Палочка" ein, glaube ich das tschetschenische Wort ist "гӀаж" (g'až). Das lesgische Name dürfte t'al heißen. Müsste man wahrscheinlich immer über Russ.-online-Wörterbücher suchen.--WajWohu (Diskussion) 16:52, 22. Jun. 2023 (CEST)
- Ja, dachte mir sowas. Danke. --AMGA 🇺🇦 (d) 21:59, 22. Jun. 2023 (CEST)
- @Amga: Oben noch kurz korrigiert: In der lateischriftlichen Variante existierte das Palotschka bereits.--WajWohu (Diskussion) 22:32, 27. Jun. 2023 (CEST)
- Ja, dachte mir sowas. Danke. --AMGA 🇺🇦 (d) 21:59, 22. Jun. 2023 (CEST)
--->8---Schnapp--->8---
(Einschub Ende — Speravir – 01:36, 24. Jun. 2023 (CEST))
- Hallo @Speravir: Beides gute Vorschläge (Wikitongues und die Phonemtabelle), kann man gern ergänzen. Phonemtabellen sind in Sprachartikeln hier Standard, wenn auch im Gegensatz zu Hörproben nicht besonders laienverträglich, eine wissenschaftliche Angelegenheit aus der Allgemeinen Linguistik. Die erste Tabelle mit Hörproben funktioniert aber leider nur mit den Beispielwörtern. Hör mal rein, Benutzer:Adamsa123 spricht da immer zuerst den Laut/das Phonem und anschließend genau diese dahinter angegebenen Beispielwörter. Ob es sinnvoll ist, noch die alten lateinischen und arabischen Buchstaben zu ergänzen, oder extra aufzuführen, überlass ich dir, bist technisch sehr versiert. Ich würde aber vorschlagen, die jetzt im Artikel stehende Alphabettafel mit rätselhaften Sternchen entweder ganz zu entfernen, oder, falls die arabischen und lateinischen Buchstaben in die andere nicht passen, das zu einer (vielleicht weiter unten ohne Sternchen stehenden) Vergleichstabelle umzubauen. Diese ganz erklärungslose Tabelle hätte dann so keinen Informationswert mehr, denhat sie jetzt schon nur begrenzt. Grüße--WajWohu (Diskussion) 10:47, 21. Jun. 2023 (CEST)
- PS: Ich bin mir sehr sicher, dass die Wikitongues-Beschreibung einen Fehler enthält: Yenal kündigt die Dialekt immer wie eine geschriebene Überschrift an. Zuerst spricht er den schapsugischen Dialekt (min. 0:00-0:19), dann den bjjedughuschen/bzhedugischen Dialekt (min. 0:20-0:40), dann eines Sprache, von der die Beschreibung behauptet, es sei die Abchasische Sprache (dem Tscherkessischen verwandt, aber seit etwa 3000 Jahren gesondert entwickelt) (min. 0:41-0:56), dann den kabardinischen Dialekt im Kaukasus (Kabardino-Balkarien und Umgebung) (min. 0:57-1:17) und zuletzt den kabardinischen Dialekt der Diaspora (1:18-Ende). Die dritte, mittlere Sprache ist aber nicht Abchasisch. Das ist der Abadzechische/Abdzachische Dialekt, den die Abadzechen/Abdzachen sprechen (auf der Karte im Artikel Tighudschiqo Qizbetsch, südöstlich der Schapsugen). Warum? Er sagt am Anfang und im Text mehrfach "Abdzachem(bze)", das ist die adygeische Bezeichnung für diese Sprachform/Dialekt, siehe adygeische Interwiki dieses Artikels: ady:КӀах Адыгабзэ, der dritte Rotlink dort "абдзэххэм" (abdzachchem). Der adygeische Name für die südlichere abchasische Sprache, die ganz anders klingt, ist ady:Абхъазыбзэ (=Abchasybze), was er aber nicht sagt. Wenn er dann Abchasich gesprochen hätte, hätte er "аҧсуа" ("ap'sua") sagen müssen, sagt aber wieder "abdzach". Da hatten die Wikitangues-Beschreiber etwas verwechselt, oder die Existenz dieses Dialekts "nicht auf dem Schrm". Hab nachgesehen, ob es beim Ursprungsvideo auf youtube jemand sagt, einer weist darauf hin.--WajWohu (Diskussion) 14:16, 21. Jun. 2023 (CEST)
- Dass die Beispiele den Audiodateien entnommen sind, war mir dann auch aufgefallen. Leider habe ich lokal die Tabelle schon bearbeitet und dabei die Spalte mit den Beispielen entfernt, tja – wer keine Arbeit hat und so. Die aktuelle Tabelle würde dann sowieso ersatzlos entfallen, das war genau mein Plan. Die Datei sollte dann wohl besser erstmal nicht in den Artikel eingebunden werden, bis das gelöst ist. Ich könnte die Phonemtabelle aber nur übernehmen und Links anpassen, aber sonst nichts dazu schreiben. Sollte trotzdem ein Abschnitt „Phonologie“ angelegt werden? — Speravir – 01:07, 22. Jun. 2023 (CEST)
- Ach, das ist ja übel und auch nicht sauber: Die Tabelle mit den historischen lateinischen und arabischen Alphabeten ist nicht etwa wirklich als Wikitabelle eingebunden, sondern ein Nutzer hat diese Tabelle anscheinend irgendwo mit MediaWiki erstellt, dann aber als Bilddatei abgespeichert: File:Adyghe language script history chart.png. Das entspricht als eindeutiger Klartextinhalt nicht dem Projektumfang von Commons (c:COM:SCOPE/DE), aber wir benötigen die Datei vorerst noch. — Speravir – 02:12, 22. Jun. 2023 (CEST)
- Trotzdem sind das alles gute Übersichten, die du gefunden hast. Mach eben erst die Aussprache-Tabelle und dann vllt. die älteren Alphabete, das wird gut.
- Was die Phonologie betrifft ist das bei dieser Sprache sehr herausfordernd, auch weil einige Phoneme nur in Dialekten existieren. Aber man muss es realistisch sehen: Im deutschen Sprachraum gibt es überhaupt keine Möglichkeit, Tscherkessisch auf universitär-linguistischen Niveau zu lernen, die einzige Kaukasiologie in Jena lehrt Georgisch und etwas unterstützend Russisch (viel grundlegende linguistische Literatur der Kaukasiologie ist auch auf Russisch verfasst). Da muss man, glaube ich nach Maikop, Naltschik, Amman, Moskau (?) oder Seattle (?) gehen. Da kann man erst einmal nur kopieren und minimal kommentieren, soweit man ergänzen kann. Die Allgemeine Linguistik hat einiges über diese Sprache (neben Ubychisch) geschrieben, weil sie phonologisch sehr weit geht (bei der Grammatik der Fälle schauen sie sich gern die Tabassaranische Sprache und Umgebung an), aber man kann die Vorarbeiten nicht umfangreich ergänzen oder korrigieren, vieles muss man übernehmen, und ich weiß nicht ob es hier im Portal:Linguistik User gibt, die ergänzen könnten. Später kann man das also grundsätzlich übernehmen, wenn Zeit ist, dann schau ich mal.--WajWohu (Diskussion) 10:01, 22. Jun. 2023 (CEST)
- Ich muss mich wegen des „eindeutigen Klartextinhalts“ revidieren: Wie mir selbst erst auffiel, als ich das Bild wieder in Wikitext konvertieren wollte (teilweise, mangels Arabisch-Kenntnissen nur Latein), ist ein Teil der Buchstaben gar nicht in Unicode kodiert und es gibt bisher keine Möglichkeit, sie auf modernen Computersystemen als Text darzustellen (es mag proprietäte, nicht allgemein kompatible Lösungen geben) – und selbst wenn, wäre noch die Frage, ob es passende, allgemein verfügbare Schriftarten gäbe. Daher ist die Erstellung einer Datei verständlich, ich würde dann aber andere Dateien in den Artikel einfügen – ich würde diese vorschlagen: Datei:Адыгейские алфавиты.PNG. Es existieren zwei Vorschläge, die noch fehlenden Vorschläge in den Nicode-Standard aufzunehmen:
- Proposal to encode Arabic characters used for Adyghe and Chechen languages; dieser Vorschlag ist von 2011 und wird in dieser Form auf keinen Fall mehr umgesetzt werden, denn die vorgeschlagenen Positionen sind unterdessen anderweitig belegt. Ich suchte nach einigen vorgeschlagenen Bezeichnungen und fand sie nicht, so dass es aussieht, dass sie auch nach 12 Jahren noch nicht übernommen wurden.
- Proposal to Encode Latin characters for old Adyghian; Vorschlag von 2022, interessanterweise nutzte der Petent einige Abbildungen von Commons, ohne das kenntlich zu machen (auch die von mir vorgeschlagene Vergleichstabelle).
- Ich hatte die lateinischen und arabischen Buchstaben in die Tabelle mit den Aussprachedateien integrieren wollen, was aber nun hinfällig ist. Ich habe teilweise Probleme bei den Übersetzungen der Aussprachebeispiele. Ich würde die Tabelle trotzdem veröffentlichen und auf Korrekturen hoffen. In Ordnung? — Speravir – 01:36, 24. Jun. 2023 (CEST)
- In Ordnung :) Ich schaue es mir dann an.
- Ich hab früher einmal Arabisch gelernt, war im Libanon und kenne auch die Sonderbuchstaben des Persischen und Osmanischen, bin in dem Bereich aber nicht sehr aktiv, aber kenne die Schrift. Ich hab mir die erste Vergleichstabellen-Datei angesehen (die aus dem zweiten Vorschlag unten kommt) und mit dem hiesigen Font unter "Sonderzeichen"-->"Arabisch, erweitert" (oben) verglichen. Die arabisch-schriftliche Entsprechung ausgerechnet der beiden Grundvokale (kyrillische Entsprechung) и und ы haben am Ende (links, beim zuletzt genannten Buchstaben ist es der ganze arabischschriftl. Buchstabe) einen Unterbogen, der sich nicht darstellen lässt. Außerdem sind die arabischschriftl. Entsprechungen zum лъ, лӀ, zum чъ, чӀ und zum Ӏ und Ӏу schlicht und einfach nicht darstellbar. Außerdem fällt im tschetschenischen Vorschlag oben im ersten Stichpunkt noch ein arabisches k mit ähnlichem kleinen Querstrich, wie beim arabischschriftl. L-Buchstaben zum лъ auf, das auch nicht darstellbar ist. Sind eben alles aufgegebene Schriftsysteme. Bei den lateinschriftlichen Entsprechungen dürfte es noch größere Probleme geben. Nein, genau deshalb die Dateien mit den Entsprechungen. Es geht nicht, das selbst zu versuchen.--WajWohu (Diskussion) 09:58, 24. Jun. 2023 (CEST)
- So, jetzt habe ich die Tabelle endlich eingefügt, damit man etwas zum Korrigieren hat. Probleme/Merkwürdigkeiten/Dinge, die man potentiell ändern könnte:
- Wie schon erwähnt, die Übersetzungen der Beispiele – ich musste ja von der englischen Übersetzung ausgehen, das bietet massives Potential für Fehler. Wenn man auf ein Adygeisch-Russisch-Wörterbuch zugreifen könnte, hätte man noch eine andere Kontrollmöglichkeit.
- Im Enwiki hat sich irgendwer bei der Transliteration für diejenige von TITUS entschieden, also die von J. Gippert, die halte ich aber für zu speziell (ɣ, ʒ, χ, ǝ?). Ich habe stattdessen die ISO-Translit. genommen, bin damit aber auch nicht so glücklich. Bei anderen Sprachen würden wir gern noch die Transkription entsprechend unserer Regeln bzw. entsprechend Kyrillisches Alphabet ergänzen, was aber hier wohl auch eher irreführend ist. Wäre die in der Quelle Transliteration of Adyghe (Adyghian) als KNAB angegebene estnische Variante nicht ein guter Versuch? Ich würde die aber zusätlich zu ISO eintragen. Andererseits könnte auch die TITUS-Transkription zusätzlich eingetragen werden, zumal wir direkt auf Herrn Gippert verweisen könnten.
- In dem Zusammenhang fiel mir auf, dass, wenn ich nicht noch mehr übersehen habe (im Sinne von: jetzt bereits wieder vergessen und bei der Nachkontrolle übersehen), zwei Buchstaben in der Tabelle fehlen. Das sind ФӀ/фӀ und Ху/ху, und nur bei letzterem gibt es eine Anmerkung, dass dieser Buchstabe nicht immer aufgeführt werde. Allerdings sind andere Buchstaben mit diese Markierung (B in der Quelle) nicht weggelassen worden. Nun gibt es auch für diese beiden Buchstaben je eine Audiodatei vom selben Urheber, nur könnte ich die Beispiele daraus nicht extrahieren, verschriftlichen und übersetzen. Nachtrag – die Audiodateien: Datei:Adygheф1.ogg und Datei:Adygheху.ogg.
- Ich habe außer der Tabelle noch etwas zum arabischen und lateinischen Alphabet geschrieben, was natürlich auch kontrolliert werden müsste.
- — Speravir – 01:58, 27. Jun. 2023 (CEST)
- @Speravir: Vielen Dank für die Arbeit.
- Für die vielen Antworten und Durchsichten brauch ich auch noch etwas Zeit :-) Grüße--WajWohu (Diskussion) 22:32, 27. Jun. 2023 (CEST)
- Eben habe ich auch die Phonologietabellen eingefügt, da gilt es natürlich ebenso, sie gegebenenfalls zu korrigieren. Was ist beispielsweise ein “plain consonant”, den ich zum „einfachen Konsonanten“ gemacht habe? Außerdem Ergänzung zu oben:
- Sollten die IPA-Zeichen in der Alphabettabelle besser verlinkt werden? Bei den vielen Kombinationen geht erfolgt aber sehr häufig direkt auf die Lsite, die im Tabellenkopf verlinkt ist. Im neu hinzugefügten Phonologieabschitt habe ich die Verlinkung mittels Vorlage erzeugen lassen, da kann man das gut nachvollziehen.
- Eventuell fehlende Transkription: Derzeit kann man nicht nachvollziehen, warum Scheretlyqo Tighudschiqo Qizbetsch so transkribiert wurde. Sieht mir irgendwie nach einer wilden Privatkombination des Artikelerstellers aus. Zum Beispiel hattest Du, WajWohu, dort kürzlich ein YouTube-Video verlinkt, der Uploader hat den Namen (mutmaßlich türkisch) als Tığujıko Kızbeç transkribiert (also mit K statt Q, was den Unterschied unserem Wikipedia-Artikel ausmacht, wobei nach KNAB und TITUS Q richtig wäre).
- — Speravir – 01:52, 29. Jun. 2023 (CEST)
- Hallo @Speravir: Zuerst zu den Fragen der Umschriften. Glückwunsch zur Verwendung des IPA, das ist immer die richtige Wahl. Was die Umfrage weiterer Umschriften betrifft, muss ich erst einmal etwas kurz nochmal klären (ohne zu wissen, dass du es schon weißt, das weiß nun wieder ich nicht :-). Es geht beim IPA um die möglichst genaue Wiedergabe der Phoneme. Bei der wissenschaftlichen Transliteration geht es um die ganz exakte Wiedergabe Buchstabe für Buchstabe (lat. litera), was geschrieben wird. Man soll genau in lateinischen Buchstaben rekonstruieren können, welche Buchstaben in der Originalschrift (hier: Kyrillisch) geschrieben werden. Beispiel aus dem Arabischen: Abū Hāschim al-Dschubbā'ī-die DMG-Transliteration hinter der arabischen Schrift zeigt genau auf, welche Buchstaben da in arabischer Schrift geschrieben werden. Das ist aber gerade in dieser Sprache mit ihren vielen Dialekten keinesfalls immer die Phonetik. Nun war die kaukasiologische wiss. Lit. lange vom Russischen mit derselben kyrillischen Schrift ohne Transliteration verfasst. Erst seit der Wende machten sich Wissenschaftler aus Ländern mit lateinischer Schrift Gedanken über ein eindeutiges Transliterationssystem, das gleichzeitig als vollständiges Transkriptionssystem für alle die zahlreichen kaukasischen Dialekte, die nicht etablierte Schriftsprachen haben, eindeutig auch dienen können. Deshalb ist das kein entweder-oder zwischen Transkription&Transliteration und IPA. Ich halte es deshalb für lohnend, neben dem IPA in der Tabelle auch ein wissenschaftliches Transliterations-/ Transkriptionssystem in einer weiteren Spalte vorzustellen, wenn nicht, nicht schlimm, IPA ist am wichtigsten, aber für Interessierte oder Fachleute sicher auch interessant, daneben so ein System vorzustellen....
- Wenn du meine Wenigkeit fragst, welches dieser Systeme am günstigsten für den Artikel ist, würde ich doch zu 100 % für "TITUS 2000" eintreten, weil ich alle anderen nie "in action" gesehen habe, weder in wiss. Literatur, noch sonst irgendwo. Das ist das System, was Jost Gippert hier verwendet, was Georgij A. Klimov oben auf S. 390 ff. verwendet, damit wird eine Witzgeschichte des letzten Sprechers der Ubychischen Sprache, Tevfik Esenç in diesem Video transkribiert, das verwendet der französisch-georgische Kaukasiologie-Professor Georges Charachidzé in diesem Video handschriftlich zur Schreibung des Ubychischen. Ich hab die anderen Transkriptions-/Transliterationssysteme nirgendwo jemals beobachtet, zumindest in der deutsch- und französischsprachigen Fachwelt ist es das absolut dominierende, wenn nicht einzige Umschriftsystem.
- Die anderen Fragen und Korrekturen mache ich später bei Gelegenheit. Danke für die sehr gute und fleißige Arbeit bisher. Beste Grüße--WajWohu (Diskussion) 23:19, 29. Jun. 2023 (CEST)
- Lieber etwas mehr erzählen, was der andere schon weiß, als andersherum. Oft hat der interessierte Laie (so wie ich) ein groben Überblick, aber es hapert im Detail. Damit zur Transkription: Ich werde die TITUS-Variante als weitere Spalte ergänzen. Du könntest ja noch dazu schreiben, warum genau diese ausgewählt wurde, entweder als weitere Fußnote (wo wir dann wohl besser auf Zahlen umstellen sollten) oder unter der Tabelle, wenn es so besser passt, etwa, weil noch andere Informationen folgen. — Speravir – 01:01, 30. Jun. 2023 (CEST)
- Ich check die Beispielwörter mit diesem Adygeisch-Russischen WB online, gleich beim 1 Wort ачъэ gab sie das richtige russ. Wort козел (Ziege) aus. Bin ja skeptisch, dass da viel Korrektur herauskommt, aber zur Sicherheit. Vielleicht gelingt es später, die gesprochenen Beispielwörter von Benutzer:Adams123 zu ФӀ/фӀ und Ху/ху zu identifizieren und zu übersetzen, nur dann würde ich die ogg-Datei ergänzen.--WajWohu (Diskussion) 23:24, 30. Jun. 2023 (CEST)
- Cool, dann kann man das mal durchgehen. Ich habe übrigens oben die zwei Audiodateien eingetragen, damit muss man nicht nach ihnen suchen.
- TITUS-Transkription ist jetzt eingetragen. Nächstes Problem(chen) damit: Einige Buchstaben, die als nur in Lehnwörten vorkommend markiert sind, werden angeblich gar nicht transkribuert. Aber wenigstens diese Lehnwörter müssen doch gelegentlich auch mal umgeschrieben werden, oder? Ich habe jedenfalls in Klammern eine Umschrift angegeben, entweder entsprechend der sonst üblichen Transkription für das Kyrillische oder von Angaben ausgehend, die für andere kaukasische Sprachen gemacht wurden. — Speravir – 02:08, 1. Jul. 2023 (CEST)
- So, jetzt habe ich die Tabelle endlich eingefügt, damit man etwas zum Korrigieren hat. Probleme/Merkwürdigkeiten/Dinge, die man potentiell ändern könnte:
- Ich muss mich wegen des „eindeutigen Klartextinhalts“ revidieren: Wie mir selbst erst auffiel, als ich das Bild wieder in Wikitext konvertieren wollte (teilweise, mangels Arabisch-Kenntnissen nur Latein), ist ein Teil der Buchstaben gar nicht in Unicode kodiert und es gibt bisher keine Möglichkeit, sie auf modernen Computersystemen als Text darzustellen (es mag proprietäte, nicht allgemein kompatible Lösungen geben) – und selbst wenn, wäre noch die Frage, ob es passende, allgemein verfügbare Schriftarten gäbe. Daher ist die Erstellung einer Datei verständlich, ich würde dann aber andere Dateien in den Artikel einfügen – ich würde diese vorschlagen: Datei:Адыгейские алфавиты.PNG. Es existieren zwei Vorschläge, die noch fehlenden Vorschläge in den Nicode-Standard aufzunehmen:
{kind=link}
{kind=link}
Übersetzungen in der Alphabet-Tabelle
[Quelltext bearbeiten]Abgetrennt vom vorigen Abschnitt. — Speravir – 04:05, 5. Jul. 2023 (CEST)
Ich bin die Übersetzungen durchgegangen. Einige der Wörter sind im von dir verlinkten WB nicht bekannt. Ich hab dann bei ru.glosbe.com und translate.academic.ru recherchiert, teilweise hab ich sogar rückwärts vom Deutschen über das Russische gesucht, trotzdem wurde ich bei wenigen nicht fündig, die ich dann nicht geändert habe. Leider habe ich nicht daran gedacht, sie zu dokumentieren, so muss ich das noch einmal nachholen (wie schon mal: Hmpf, wer keine Arbeit hat, macht sich welche). Kennst Du Шаов Ж.А. Адыгейско-Русский словарь? (Und, erst eben von mir selbst beachtet, was noch als Tipps darunter steht?) Schwierig bleibt für mich das Beispiel хьандзуачӀ, das laut diesem Wörterbuch russisch низ скирда bedeutet (скирд ist das Beispiel davor). — Speravir – 01:53, 2. Jul. 2023 (CEST)
- Oh, jetzt bist du sehr schnell, seit ich das letzte geschrieben habe, war ich nicht mehr online, unterwegs, hab noch nicht angefangen.
- Ja, konjugierte Verben, wie das 2. Beispielwort, sind natürlich ein Problem, das listen WB normalerweise nicht so, dazu muss man die Nennform und die Regeln der Konjugation kennen.
- Ich check das auch einmal und vergleiche sie mit Übersetzungen vorher und nachher. Bitte nicht als Krittelei missverstehen, wenn ich zu einem Wort nichts schreibe, bin ich vollkommen einverstanden (was man ja nicht jedesmal betonen muss), oder weiß es selbst nichts dazu (dito :-), ich schreibe nur etwas, wenn ich es kritisch sehe.
- Das 2. Beispielwort bei "Гу", гущыӀ würde ich nicht als "Wort, Sprache", also im Sinne von "(Adygeische/Deutsche/Russische usw.) Sprache" verstehen. Der semantische Komplex, den das zuerst genannte WB angibt, heißt eher "Wort, Rede, Gesprochenes" (russ. речь heißt primär "Rede/Gesprochenes" im übertragenen Sinne, wie in der dt. Redewendung "zur Sprache bringen", in einigen anderen slaw. Sprachen heißt es wirklich "Sprache", wie man es primär versteht, aber auf Russ. ist das eher "Rede". "Sprache" heißt hier "язык". Das zeigt sich auch in der 5. Bedeutung (ganz zuletzt stehen in WB sehr spezielle Bedeutungen) "дать слово" (Wort erteilen), offenbar ist dann "гущыӀ" eine feste adygeische Redewendung. Wenn sich also Tscherkessen zu Versammlungen/Treffen/Kongressen/Ratsversammlungen trafen (das gab es schon in der tscherkessischen Geschichte des 18./19. Jh.s sehr häufig), sagt der Versammlungsleiter/Ratspräsident einfach z.B. "гущыӀ Къызбэч!", was dann heißt "Das Wort [hat] Qizbetsch!"/"[Ich erteile] das Wort/die Rede [an] Qizbetsch!". Ich würde es "Wort/Rede" oder "Wort/Gesprochenes" übersetzen, das erste fänd ich etwas eleganter in dem knappen Rahmen, ist aber egal. Grüße--WajWohu (Diskussion) 22:48, 2. Jul. 2023 (CEST)
- гъунджэ (Spiegel?) hat das oben verlinkte WB nicht. Schaue später nochmal in den von dir empfohlenen WB.--WajWohu (Diskussion) 23:10, 2. Jul. 2023 (CEST)
- дзын (werfen) ist ein bissel schwierig, offenbar wird davor immer gesagt, was geworfen wird. Als Nebenbedeutung darunter, dass auch Wurzeln in dieser Sprache nicht geschlagen, sondern geworfen werden, das letzte heißt "erraten", kann aber nicht übersetzen, was dabei konkret geworfen wird. Ich würde es als "[etw.] werfen" übersetzen, was das WB wiedergibt, einverstanden?--WajWohu (Diskussion) 23:27, 2. Jul. 2023 (CEST)
- Woher hast du die Übersetzungen von "хьандзу („Schober“), хьандзуачӀ („Heuhaufen [niedriger Schober]“)", die du oben als Problem bezeichnest? Das erste heißt jedenfalls hier ganz allgemein "Stapel, Haufen", das 2. Wort hat dieses WB nicht... Ich hör heute erstmal auf :-)--WajWohu (Diskussion) 23:41, 2. Jul. 2023 (CEST)
- Keine Sorge, ich sehe das nicht als Krittelei. Zu einzelnen Punkten:
- гъунджэ als „Spiegel“: Das ist dann eines der Wörter, wo ich rückwärts vorgegangen bin. Spiegel → russ. зеркало (mit PONS-Wörterbuch, ich bin nicht [mehr ?] so gut, das [noch] zu wissen) → gefunden bei Glosbe (ru.glosbe.com/ru/ady): зеркало als dritte Variante.
- хьандзу: dovlet.info, хьандзу übersetzt als стог, скирд. PONS Russisch-Deutsch: стог „Schober, Heuschober“ (Langenscheidt nur „Schober“), скирд „Schober“ (Langenscheidt dito); beachte, dass die englische Übersetzung „rick“ ist, was dem nicht widerspricht. Ich finde nun aber in der Tat auch „Heuhaufen, Strohhaufen“ als Übersetzung: стог (dict.cc, Übersetzung Russisch-Deutsch), стог (LEO Russisch ⇔ Deutsch).
- Zu хьандзуачӀ hatte ich oben schon etwas geschrieben, aber noch einmal in der Auflistung: Gefunden in Шаов Ж.А. Адыгейско-Русский словарь (nett auch die Transkription des russ. Namen ins Adygeische), das laut diesem Wörterbuch russisch низ скирда bedeutet. Zu низ fand ich keine Übersetzung, aber jetzt eben: низ (LEO) – meine Übersetzung kann also so nicht stehen bleiben. Nur was ist die „Unterseite eines Schobers/Heuhaufens“?
- — Speravir – 02:02, 3. Jul. 2023 (CEST)
- @Amga: Deine Expertise zum letzten Punkt darüber ist einmal gefragt. Was ist russisch: низ скирда? Ich würde ja vermuten, dass es der Schoberboden, der Boden eines Heuschobers ist?--WajWohu (Diskussion) 23:28, 5. Jul. 2023 (CEST)
- @WajWohu Ja, würde ich mir auch so erklären, weil "unten"/"Unterteil" - was soll da sonst sein. Wobei ich bislang nur стог "aktiv" kannte. Sind schließlich ziemlich dörfliche "Fachbegriffe". (Der Unterschied ist wohl, das ein скирд - alternativ скирда - eher länglich, ein стог eher rund ist. Стог ist auch insgesamt häufiger.) --AMGA 🇺🇦 (d) 07:49, 8. Jul. 2023 (CEST)
- @Amga: Deine Expertise zum letzten Punkt darüber ist einmal gefragt. Was ist russisch: низ скирда? Ich würde ja vermuten, dass es der Schoberboden, der Boden eines Heuschobers ist?--WajWohu (Diskussion) 23:28, 5. Jul. 2023 (CEST)
- Ich sehe schon, das Thema ist bei dir sogar in sehr guten Händen, da muss man nicht so viel erklären.
- жьао („Schatten“) hab ich noch nicht gefunden.
- ку heißt „Karren, Wagen“? Dovlet-WB übersetzt es nur als "zuleitung", "Zufuhr".
- къалэ („Stadt“) ist übrigens ein Lehnwort aus dem Arabischen, sollte man das hier erwähnen?
- мощ („dies, das“) hab ich noch nicht gefunden.
- пэ wird nicht nur als „Nase“ (Substantiv) übersetzt, wird auch als Adjektiv übersetzt (nasal, nasig, wie auch immer).
- пӀэшъхьагъ („Kissen“) hab ich noch nicht gefunden.
- Ich mach bei р später weiter. Grüße--WajWohu (Diskussion) 22:55, 3. Jul. 2023 (CEST)
- Ich schreib das erstmal für mich hin, entgegen dem, was ich oben geschrieben habe: das Verb рикӀэн („gießen, schütten“) und риӀон („erzählen“) kennt Dovlet auch nicht, ich schau später noch in dene WB.
- Interessant sind die beiden Beispiele unter С с- сэ heißt "ich", aber homonym auch "Säbel" (weiß nicht, ob ganz allgemein, oder die orientalischen Krummsäbel. сэшхо ist dagegen die Schaschka, ein oft als kosakisch bezeichneter spezieller Säbel, der aber ursprünglich tscherkessisch ist. (Die Kosaken besonders in Südrussland haben sehr viel von den Tscherkessen übernommen, besonders den kompletten Kleidungsstil - Papacha, Tschocha, Burka (Männerumhang) usw. - das ist auch in Russland allgemein bekannt.)
- тӀурыс heißt das, nicht allgemein "alt", sondern eher "bejahrt, betagt" in der 2. Bedeutung "gebraucht, abgewetzt"...
- убэн („stampfen; lästern, tratschen“) würde ich das erste Teilwort eher als "rammen" übetragen, eigentlich ein guter Bedeutungszusammenhang.
- пхъэн (säen) hat dieses 1. WB nicht.
- шъугъуалэ („neidisch“), muss ich noch woanders suchen.
- Ist ыкӀи wirklich „und, auch, sowie“, oder eher "geeint", "verbunden", besser "Bund"?
- Ӏэтаж („Geschoss, Etage“) ist ein Lehnwort aus dem Französischen, soll man das erwähnen?
- Bis hierher, sieht im ersten Moment viel aus, ist aber bei insgesamt über 150 Beispielwörtern nicht viel und manche Hinweise sind auch eher marginal. Ich streiche die dann weg und bei denen, die ich nicht gefunden habe, schau ich nochmal in die anderen WB. Grüße--WajWohu (Diskussion) 23:13, 4. Jul. 2023 (CEST)
- Antworten, nicht ganz chronologisch, wenn ich zu einem Punkt nichts sage, darfst Du das als stille Zustimmung ansehen.
- Lehnwörter: Kann man erwähnen, so wie ich die russischen Vorlagen für einige Wörter eingetragen habe. Bei Ӏэтаж ist es wohl besser, „Etage, Geschoss“ zu schreiben, damit man weniger Gefahr läuft, „Geschoss“ misszuverstehen. Kann ich natürlich auch selber ändern.
- Die Schaschka am besten verlinkt eintragen, so wie schon Jod und Schober. Bei letzterem sollte man den Heuhaufen ergänzen. Auch das kann ich natürlich selber ändern.
- Zu жьао: Bei Glosbe, жьао, als тень übersetzt. Kann allerdings auch „Geist“ und „Spur“ heißen. Die fehlen also noch. Auch das kann … ;)
- Zu ку: Dovlet übersetzt als подвода. PONS, подво́да: „Pferdewagen, Bauernwagen“; Langenscheidt, подвода: „Fuhrwerk“, auch gut, das habe ich mir aber letztens nicht angesehen. Die englische Übersetzung ist „cart“.
- Zu пхъэн: Bei Shaov/Schaow steht: «пхъэн см. пхъын.» Und bei пхъын steht dann «1. сеять; […] 2. сеяние» (Hmm, wenn ich das mit anderen Beispielen vergleiche, ist das doch aber schon eine [Verb-]Infinitivendung? Ach so, „säen, das Säen“.). Dort hatte ich aber gar nicht nachgesehen, sondern bei translate.academic.ru (ru-ady): пхъэн, siehe Punkt 3. Was mir da nicht aufgefallen war, ist, dass das Umschalten von Russisch-Adygeisch zu Adygeisch-Russisch nicht funktioniert. Allerdings ist das Краткий русско-адыгейский словарь als Quelle angegeben und ich bemerke eben gerade, dass dies verlinkt ist.
- Ähnlich zu шъугъуалэ: шъугъуалэ – завистливый.
- Zu ыкӀи: Bei Glosbe, ыкӀи, «да» und «и». Bei Schaow steht «союс и», die Kursivsetzung von союс ist schon bei ihm vorhanden, was bei Dovlet fehlt.
- Zu мощ: Ich fand bei translate.academic.ru (ru-ady) unter этот in Punkt 3 die Form мыщ (dort stehen, wie gesagt, auch die Quellen) und dachte, das könnte dann stimmen. Allerdings steht unter это nichts in der Richtung.
- Zu пӀэшъхьагъ („Kissen“) hab ich auch nichts. Vom Deutschen ausgehend kommt man über подушка (Glosbe) stattdessen zu шъхьантэ. Schaow hat das Lemma шъхьант mit Übersetzung подушка.
- Zu рикӀэн („gießen, schütten“) und риӀон („erzählen“): Ebenso nichts gefunden.
- Schluss für jetzt. — Speravir – 04:05, 5. Jul. 2023 (CEST)
- Also, ich muss schon mal sagen, du hast das super gemacht, in sehr viel kürzerer Zeit, als ich hinterherkam. Drei Wörter fehlen noch, aber vielleicht notfalls glauben wir die eben... Ich hab oben mal kurz etwas nachgefragt. Hoffentlich lässt sich das finden.--WajWohu (Diskussion) 23:28, 5. Jul. 2023 (CEST)
- Zu Glosbe wollte ich noch etwas loswerden. Wir haben hier nicht viel andere Möglichkeiten zur Auswahl, aber sonst, wo ich es besser einschätzen kann, vermeide ich Glosbe eher. Ein (Extrem?-)Beispiel: Diese Änderung von mir erfolgte zu einem großen Teil wegen des, man kann es nicht anders sagen, fehlerhaften Beleges zu Glosbe la-de, nämlich detectum, was anders, als es dort steht, auf keinen Fall „Detektiv“ bedeutet. — Speravir – 00:06, 6. Jul. 2023 (CEST)
- Also, ich muss schon mal sagen, du hast das super gemacht, in sehr viel kürzerer Zeit, als ich hinterherkam. Drei Wörter fehlen noch, aber vielleicht notfalls glauben wir die eben... Ich hab oben mal kurz etwas nachgefragt. Hoffentlich lässt sich das finden.--WajWohu (Diskussion) 23:28, 5. Jul. 2023 (CEST)
- Antworten, nicht ganz chronologisch, wenn ich zu einem Punkt nichts sage, darfst Du das als stille Zustimmung ansehen.
- Keine Sorge, ich sehe das nicht als Krittelei. Zu einzelnen Punkten:
Zusatzphoneme und Beispiele
[Quelltext bearbeiten]- Hallo @Speravir:, wir hatten ja oben gesehen, dass die Phoneme ФӀ/фӀ und Ху/ху von Adamsa123 (seiner Selbstbeschreibung auf Commons zufolge ein israelischer Tscherkesse, dass nur, weil ich zumindest beim Г г individuelle oder dialektale/akzentverursachte Eigenheiten hat, er spricht da eher ein /ɡ/, als ein /ɣ/, müssen wir notfalls mit anderen Aufnahmen vergleichen) auch mit ogg-Dateien mit Beispielwörtern aufgenommen hat, die er aber nicht übersetzt. Ich setze die einfach erst einmal hier ein, wir können einfach versuchen zu erkennen, wie sie geschrieben werden, um dann nach Übersetzungen zu suchen. Falls das nicht gelingt, gäbe es die Alternative, die ogg-Dateien ohne Beispielwörter, die ich darunter setze, zu verwenden.
- ФӀ/фӀ
- Beispielwort 1: фӀы
- Beispielwort 2: фӀыцӀэ
- Ху/ху
- Beispielwort 1: хуабэ
- Beispielwort 2: махо
- Beispielwort 3: хужьы
- Für die Frage, ob und wie das in die Tabelle kommt, wäre es bei Gelegenheit sinnvoll die Aussage in Fußnote B von Jost Gippert mit Alphabetübersichten zu überprüfen (und die Leerstelle des TITUS2000 bei ФӀ/фӀ kläreny, aber heute nicht mehr). Grüße--WajWohu (Diskussion) 23:12, 7. Jul. 2023 (CEST)
- Da bin ich leider der falsche Ansprechpartner, das geht weit über das, was ich beherrsche. Zu Adamsa123: Er hat, soweit ich das sehe, auch die englischen Übersetzungen eingefügt. Er war im Januar 2023 noch im Enwiki aktiv. Vielleicht liest er weiterhin passiv und es lohnt sich, ihn direkt anzufragen. Ich fand noch den User Blegojcaner, der seine Sprachenkenntnis im Enwiki auf Niveau ady-2 einschätzt und dort zuletzt am 27. Juni aktiv war, in der türkischen und adygeischen Wikipedia sogar in den letzten Tagen. Oha, ich sehe gerade, dass er sich in der adygeischen Wikipedia sogar in ady-4 einstuft. Die Varianten ohne Beispiel wären sonst wirklich der Notnagel. — Speravir – 01:36, 8. Jul. 2023 (CEST)
- Wo sind die englischen Übersetzungen? Ich finde sie nicht.--WajWohu (Diskussion) 06:36, 8. Jul. 2023 (CEST)
- Da, wo ich die Tabelle hierher übertragen (aber teilweise abgeändert) habe, en:Adyghe language#Orthography. Adamsa123 hat ja auch die Audiodateien selbst eingefügt. Insofern ist es auch merkwürdig, dass er die zwei noch fehlenden nicht eingetragen hat. — Speravir – 02:01, 9. Jul. 2023 (CEST)
- @Speravir: :-D Nein, jetzt haben wir uns missverstanden, das meine ich nicht. Dass die Übersetzungen ganz allgemein aus dem englischen Artikel stammen, die du dann gründlich überprüft hast, weiß ich. Es ging mir nur um die Beispielwörter, die Adamsa123 in den jeweils ersten Hörprobe nach Aussprache des Phonems selbst vorspricht. Da hat er, soweit ich das überblicke, nirgendwo die englische Übersetzung oder auch nur die adygeisch-kyrillische Schreibung hinterlegt, nicht in en:WP, nicht auf commons und nicht auch verschiedenen Alphabet-Videos, die ich von ihm auf youtube gesehen habe. Da gibt es nur die Möglichkeit, ihn selbst zu fragen (nicht alle User, besonders in de:WP, regieren auf Nachfragen oder einige antworten auch sehr spät) oder wir hören genau hin, schreiben sie auf Kyrillisch und übersetzen sie (das müsste machbar sein, deshalb hab ich sie oben rein gesetzt).
- Nach allem, was ich bisher gelesen und verglichen habe, hab ich es zwar nicht schriftlich nachgelesen, warum Adamsa123 sie nicht ins Alphabet eingefügt hat und warum sie oft nicht im Alphabet ergänzt werden, kann es mir aber sehr gut denken. Jost Gippert schreibt die Aussage in Fußnote B: "The characters кӀу, ху, шӀу denote distinct phonemes but are sometimes not represented in the alphabet. There are also other variations of the Adyghian alphabet." Außerdem hat das von ihm mit entworfene TITUS 2000-Transkriptionssystem bei ФӀ/фӀ sogar eine Leerstelle, einen Strich.
- Wenn man genau das фӀ in der Hörprobe oben anhört, ist ziemlich klar, dass da zwei Phoneme direkt nacheinander gesprachen werden ф + Ӏ, also f und danach der Laut, den das Palotschka umschreibt, ohne dass sich die Phoneme gegenseitig verfärben oder enger gesprochen werden. Da fanden es die Entwerfer des TITUS 2000-Systems sinnlos ein eigenes Graphem zur Umschreibung/Transliteration zu entwerfen. Man muss einfach nur beide Transliterations-Zeichen für ф und Ӏ (Palotschka) nacheinander schreiben, was in dem System so aussieht: fˀ (f für ф und ˀ für den Laut des Palotschka). Genau deshalb wird фӀ auch meistens nicht mehr im Alphabet aufgeführt. Warum es selten trotzdem im Alphabet angegeben wird, ist offensichtlich: Im 1927-38 gab es noch einen speziell kreierten Buchstaben, siehe Vergleichstabelle des lateinischen und kyrillischen Alphabets: ein nach links gedrehtes kleines f. Aus Traditionsgründen wird es selten noch ergänzt, ist aber phonetisch ähnlich überflüssig, wie das lateinische x.
- Etwas ähnlich ist es bei den von Gippert erwähnten кӀу, ху, шӀу: da wird eigentlich immer кӀ+у, х+у und шӀ+у nacheinander gesprochen, werden deshalb manchmal nicht im Alphabet aufgeführt. Allerdings kann ich Gippert verstehen, warum er sie trotzdem als "distinct phonemes" betrachtet: Es gibt ja eigentlich kein wirkliches u bzw. Halbvokal w im Adygeischen. Hier treten sie nur nach speziellen Konsonanten verkürzt gesprochen auf, sind also das, was das IPA in vielen Sprachen als kurzes, hochgestellt geschriebenes ʷ wiedergibt, deshalb doch ein eigenes Phonem. Ru:WP gibt dagegen an, dass das alles Dialektphoneme sind (siehe unten).
- Deshalb würde ich einfach vorschlagen, wir bringen an фӀ, кӀу, ху, шӀу eine Anmerkung an, dass sie nicht immer im Alphabet aufgeführt werden und ergänzen фӀ und ху nur, wenn wir die Beispielwörter verschriftlicht und übersetzt bekommen. Gruß--WajWohu (Diskussion) 00:06, 10. Jul. 2023 (CEST)
- Ich habe gerade anderes zu tun, deshalb nur kurz: Soweit ich das nachvollziehen kann, hat Adamsa123 nicht nur die Audiodateien in den Enwiki-Artikel eingefügt, sondern dazu auch die adygeisch-kyrillische Schreibung und die englische Übersetzung der Hörbeispiele. — Speravir – 03:04, 11. Jul. 2023 (CEST)
- Ja, aber nicht für ФӀ фӀ und Ху ху, aber ich sehe schon, du bist gerade abgelenkt, ich versuch es einmal.--WajWohu (Diskussion) 08:57, 11. Jul. 2023 (CEST) PS: ru:WP hat sie hier als "Dialektbuchstaben" mit Schreibung, aber ohne Übersetzung, die lassen sich auch nicht übersetzen, weil es offenbar Dialektwörter sind. Da muss ich Adamsa123 wohl direkt fragen.--WajWohu (Diskussion) 09:37, 11. Jul. 2023 (CEST) Ich hab User:Adamsa123 auf commons direkt gefragt, die Antwort kann ein bisschen dauern, Adamsa123 war das letzte mal im Juni auf en:WP aktiv, auf commons 2020. Aber mehr kann ich nicht machen, nach ru:WP sind das alles Dialektwörter, kein einziges konnte mir eines der Adygeisch-Wörterbücher online übersetzen, die hatten sie alle nicht.--WajWohu (Diskussion) 14:00, 11. Jul. 2023 (CEST)
- Ich habe gerade anderes zu tun, deshalb nur kurz: Soweit ich das nachvollziehen kann, hat Adamsa123 nicht nur die Audiodateien in den Enwiki-Artikel eingefügt, sondern dazu auch die adygeisch-kyrillische Schreibung und die englische Übersetzung der Hörbeispiele. — Speravir – 03:04, 11. Jul. 2023 (CEST)
- Da, wo ich die Tabelle hierher übertragen (aber teilweise abgeändert) habe, en:Adyghe language#Orthography. Adamsa123 hat ja auch die Audiodateien selbst eingefügt. Insofern ist es auch merkwürdig, dass er die zwei noch fehlenden nicht eingetragen hat. — Speravir – 02:01, 9. Jul. 2023 (CEST)
- Wo sind die englischen Übersetzungen? Ich finde sie nicht.--WajWohu (Diskussion) 06:36, 8. Jul. 2023 (CEST)
- Da bin ich leider der falsche Ansprechpartner, das geht weit über das, was ich beherrsche. Zu Adamsa123: Er hat, soweit ich das sehe, auch die englischen Übersetzungen eingefügt. Er war im Januar 2023 noch im Enwiki aktiv. Vielleicht liest er weiterhin passiv und es lohnt sich, ihn direkt anzufragen. Ich fand noch den User Blegojcaner, der seine Sprachenkenntnis im Enwiki auf Niveau ady-2 einschätzt und dort zuletzt am 27. Juni aktiv war, in der türkischen und adygeischen Wikipedia sogar in den letzten Tagen. Oha, ich sehe gerade, dass er sich in der adygeischen Wikipedia sogar in ady-4 einstuft. Die Varianten ohne Beispiel wären sonst wirklich der Notnagel. — Speravir – 01:36, 8. Jul. 2023 (CEST)
{kind=link}
Phonetische Beschreibungen
[Quelltext bearbeiten]@Kenneth Wehr, WajWohu: Was mir gestern erst auffiel: Die IPA-Lautung für die Vokale ist unter Phonologie und in der Alphabettabelle derzeit teilweise unterschiedlich. Könnte das an der Dialektproblematik liegen? — Speravir – 23:04, 14. Jul. 2023 (CEST)
- Wenn ich mir die Hörbeispiele zu ы und э anhöre, sind das schon die richtigen IPA-Zeichen. Warum die anderen so abweichen, weiß ich nicht. Ich füge demnächst noch etwas wiss. Lit. ein.--WajWohu (Diskussion) 23:50, 14. Jul. 2023 (CEST)
- Was da vorherrscht, kann ich nicht bewerten, aber es sollte durchaus einheitlich sein. --Kenneth Wehr (Diskussion) 10:53, 15. Jul. 2023 (CEST)
Seltenere Konsonanten werden mit den nachgestellten Hilfszeichen ъ, ь, Ӏ und у näher bestimmt. Das Weichheitszeichen ь kennzeichnet eine „Erweichung“ des Konsonanten (meistens Palatalisierung), das Hartheitszeichen ъ bezeichnet eine Lautverhärtung (meistens Ejektive), das Palotschka Ӏ kennzeichnet einen mit gesprochenen Stimmabsatz (Glottisschlag) und das Hilfszeichen у kennzeichnet den mit gesprochenen Halbvokal w/u ([ʷ]). Das scheint ja nicht der Fall zu sein, da ь und ъ Laute nur abwandeln ohne erkennbares System (bspw. ъ bei г, к und х Verschiebung nach hinten, bei ж, ч und ш Retroflexierung, bei л Frikativierung), während Ӏ immer für die Ejektivierung zuständig ist, aber als eigener Buchstabe wird da der Glottisschlag genannt (im Beispiel dann aber wieder in Verbindung mit einem Konsonanten). --Kenneth Wehr (Diskussion) 10:53, 15. Jul. 2023 (CEST)
- Ja, du hast Recht, "Ejektive" war ein eher missratenes Beispiel, bin auch eher historisch, als linguistisch "unterwegs", unabhängig davon, was ich früher mal in Nebenfächern studiert hab :) Könnte man Plosive als Beispiel für "Verhärtung" schreiben? Ich mach es einfach provisorisch...
- Was die Bestimmung anhand der Hörbeispiele betrifft, wäre ich manchmal vorsichtig, der Sprecher User:Adamsa123 scheint einige "Abschleifungen" zu haben, möglicherweise als individuelle Eigenart oder das Ergebnis "kontaktbedingten Sprachwandels". Da würde ich eher die IPA-Zeichen zur Grundlage nehmen, oder auch dieses unter "Weblinks" aufgeführte Video nehmen, die sprechen ja ab min. 1:00 auch das gesamte Alphabet durch. Die scheinen es etwas "ungeschliffener" auszusprechen. Z.B. spricht er, wie auf der Nachbardiskussion schon geschrieben, das Г г wie IPA: ɡ, es ist aber eigentlich ein ɣ, also schon vorher "weit hinten", was man dann da unter Гъ гъ hört ist schon irgendwie eine "Verhärtung" (Wie nennt man das hier? Uvularisierung?). Das Къ къ scheint mir Adamsa123 deutlich "zu weich" auszusprechen, es ist das IPA: q (Stimmloser uvularer Plosiv, wie ich es auch vom arabischen Qāf gut kenne), so wird es aber nicht gesprochen. Ich würde also zur genauen Erkennung mehr auf die IPA-Symbole und das oben verlinkte Video bauen.
- Ich mach mich dann erst einmal über die Vorstellung der Dialekte her, bei Phonetik sehe ich schon, bist du wirklich gut... Grüße--WajWohu (Diskussion) 13:50, 15. Jul. 2023 (CEST)
Kapitel über Dialekte
[Quelltext bearbeiten]Ich könnte bei Gelegenheit noch eine Aufzählung der Dialekte und ihre Verbreitung ergänzen. Der Hinweis zu dem Wikitongue:Yenal speaking Circassian ist von Daniel Bögre Udell hier beantwortet worden. Er will es aber zur Sicherheit nochmal mit dem Videoautor und Sprecher selbst klären. Wohin kommt das Dialekt-Kapitel dann? Mit der Wikitongues-Datei zusammen an den Anfang oder ans Ende? Grüße--WajWohu (Diskussion) 23:28, 5. Jul. 2023 (CEST)
- Tob dich aus (als ob ich das Wissen hätte, da Veto einzulegen …). Gern auch zu den Besonderheiten, die zu diesen kombinierten Buchstaben des Alphabets führen und die Transkription so schwierig machen. Wohin das Kapitel soll? Vielleicht als völlig eigener Abschnitt oder unter Phonologie oder als Unterabschnitt davon? Und gut, dass Du bei dem Video am Ball bleibst. — Speravir – 00:06, 6. Jul. 2023 (CEST)
Status in Rojava
[Quelltext bearbeiten]Laut einiger anderen Wikipedia wie die türkischsprachige und englischsprachige Wikipedia ist Adygeisch in Manbidsch also in Rojava anerkannte Amtssprache. --Avestaboy (Diskussion) 15:32, 19. Jun. 2024 (CEST)
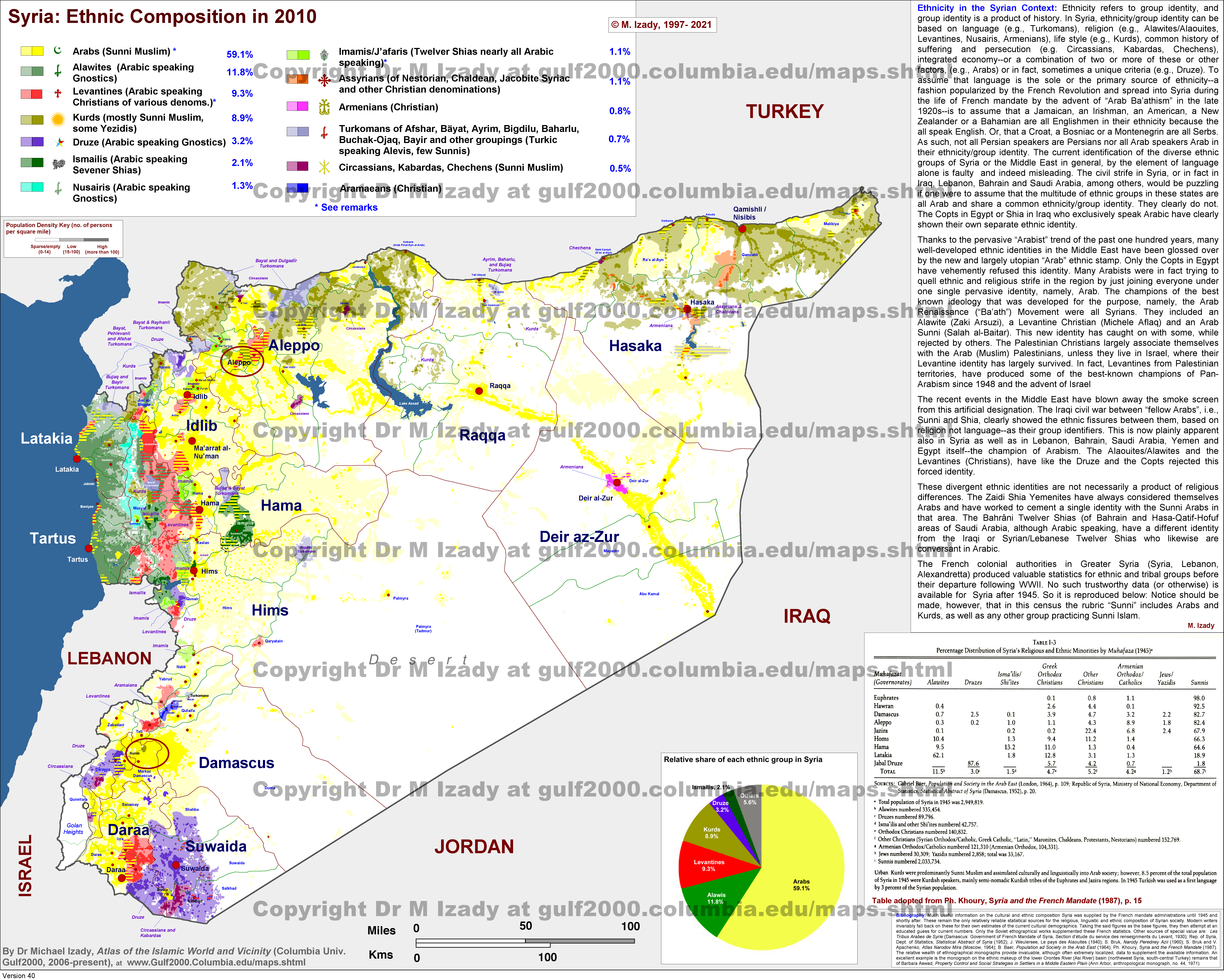
- Hallo @Avestaboy: so, wie ich das verstehe, ist Adygeisch dort eine anerkannte Minderheitensprache, ähnlich, wie es sie in der EU gibt, also es darf Schulen, Medien usw. auf Adygeisch geben, aber es scheint keine staatliche Amtssprache. Adygeischsprachige Tscherkessen sind neben Kurmandschi-sprachigen Kurden und Arabern eindeutig die zahlreichsten und relevantesten Bevölkerungsgruppen der Region um Manbidsch, siehe auch diese Karte von Mikael Izady an der Columbia University. Diesen Status hat es aber auch in Jordanien und Israel. Andere anerkannte Minderheitensprachen in Rojava sind daneben Turkmenisch (mehr dem Türkischen entsprechend, nicht die mittelasiatische Variante) und Armenisch. Die Amtssprachen von Rojava (die also in allen Ämtern und offiziellen Dokumenten verwendet werden dürfen) sind ganz allgemein Kurmandschi, Arabisch und klassisches (aramäisches) Syrisch. So etwa erklärt es auch diese Rojava-eigene Nachrichtenwebseite ("Dreisprachigkeit" und weitere entfaltete Sprachen). Ich finde aber auch für den Kanton Manbidsch keine Hinweise bisher, dass dort als staatliche Amtssprache Adygeisch offiziell dazu käme. Die Kantonswappen sind alle Kurmandschi und Arabisch beschriftet, nur der Kanton Jazira im Osten, wo auch eine relevante Zahl syrischsprachiger Aramäer/Assyrer lebt, hat auch eine syrisch-aramäische Beschriftung. Ob man den Status als Minderheitsprache ergänzt, bin ich offen, aber für Amtssprache hab ich bisher keinen Beleg gefunden. Grüße--WajWohu (Diskussion) 16:56, 19. Jun. 2024 (CEST)
{kind=link}